


🥉 Unsloth releases new GRPO algorithms that enable 10x longer context lengths & 90% less VRAM
Unsloth's GRPO slashes VRAM use, SigLIP 2 enhances vision-language, OpenAI’s Operator expands, Test-time-scaling boosts small models, while DeepSeek and vLLM drive AI efficiency and openness.

Read time: 8 min 42 seconds
📚 Browse past editions here.
( I write daily for my 112K+ AI-pro audience, with 4.5M+ weekly views. Noise-free, actionable, applied-AI developments only. ).
⚡In today’s Edition (21-Feb-2025):
🥉 Unsloth releases new GRPO algorithms that enable 10x longer context lengths & 90% less VRAM for training Reasoning Models.
🏆 Google Releases SigLIP 2: A better multilingual vision language encoder
📡 OpenAI rolls out its AI agent, Operator, in several countries
🧠A 1B-param model can outmaneuver a 405B-param LLM in tough math tasks using test-time scaling (TTS)
🗞️ Byte-Size Briefs:
DeepSeek to open-source 5 AI repositories, boosting transparency and education.
vLLM v0.7.3 adds DeepSeek’s Multi-Token Prediction, enabling 69% faster inference.
🛠️ Opinion - Now you can ingest fresh X (Tweets) data through Grok 3 and crafts authentic pieces blending live user opinions
🥉 Unsloth releases new GRPO algorithms that enable 10x longer context lengths & 90% less VRAM for training Reasoning Models.
🎯 The Brief
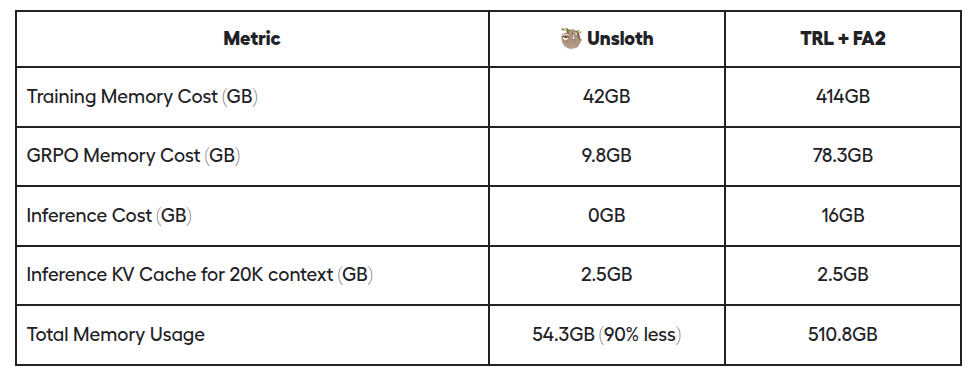
Unsloth has released a memory-efficient GRPO algorithm that enables 10x longer context lengths while cutting VRAM usage by 90%. This update allows training Qwen2.5-1.5B with just 5GB VRAM, compared to 7GB previously. For Llama 3.1 (8B) at 20K context, VRAM usage drops from 510GB to 54GB. These optimizations significantly lower hardware requirements for training reasoning models. And now you can train your own reasoning model with just 5GB VRAM for Qwen2.5 (1.5B) - down from 7GB in our previous GRPO release 2 weeks ago!
⚙️ The Details (Under-the-hood details of this massive efficiency gain)
• Unsloth begins by incorporating a specialized “linear cross-entropy” approach, adapted from Horace He’s ideas, into the GRPO procedure. This adaptation reduces the size of the logit tensors that must be stored when calculating the reverse KL divergence for multiple generated responses. By only handling cross-entropy in a more compressed form, the algorithm sidesteps the large VRAM overhead typically required when performing standard GRPO on all tokens.
• They then tackle mixed precision intricacies head-on. Simply switching to half or even lower precision can cause overflow and underflow problems, especially when exponentiating logits or working with large batch sizes. Unsloth’s system includes automatic scaling for float16 and float8 that guards against numerical instability. Through careful handling of partial sums and re-scaling steps, the algorithm avoids catastrophic rounding errors.
• Another major factor is Unsloth’s gradient checkpointing logic. Ordinarily, storing intermediate activations for backpropagation grows unmanageably large if you generate multiple candidate responses (for example, eight or more generations per prompt). Unsloth’s approach selectively offloads those activations to host memory (CPU RAM) as soon as they’re not immediately needed on the GPU, then re-fetches them later for gradient computation. This keeps GPU usage near the level you would see for basic inference, rather than ballooning to many times that size.
• Finally, Unsloth merges the GPU memory pool used by the training code with that of the vLLM inference engine. In many frameworks, the model sits in two separate memory buffers—one for forward inference, another for the trainer’s internal overhead. By ensuring that both processes share the same memory resources, Unsloth prevents duplicate copies of parameters, further reducing VRAM usage.
→ Unsloth also provides full logging for reward functions and removes manual GRPO patching. After these updates, users can now run Perplexity’s R1-1776 model locally, a DeepSeek-R1 fine-tune without censorship.
🏆 Google Releases SigLIP 2: A better multilingual vision language encoder

Google DeepMind released SigLIP 2 on Hugging Face, an upgraded vision-language model that boosts zero-shot classification, retrieval, and question answering through advanced training objectives and flexible resolution support.
🎯 The Brief
Google DeepMind released SigLIP 2 on Hugging Face, an upgraded vision-language model improving zero-shot classification, retrieval, and question answering. It integrates better location awareness, flexible image resolution, and stronger local representations while maintaining robust vision-text alignment. This reduces the need for separate models or excessive fine-tuning, simplifying OCR, document processing, and general classification. All the models are here.
⚙️ The Details
→ Better Visual Grounding: SigLIP 2 adds a text decoder to the image encoder, introducing captioning, bounding box prediction, and region-specific caption generation. This enhances spatial awareness, improving tasks like object detection and OCR.
→ Fine-Grained Semantics: Uses self-supervised learning with masked patch prediction and student-teacher comparisons to enhance local representations while keeping vision-text alignment intact.
→ Dynamic Resolutions: Supports fixed-resolution and NaFlex (native flexible) modes, allowing varied aspect ratios without distortion, especially useful for OCR and document processing.
→ Performance & Scale: Offers 1B parameters, backward compatibility with SigLIP, and boosts zero-shot learning, retrieval, and VQA. The dynamic resolution approach enhances usability for real-world multimodal tasks.
What’s so big deal about it.
It tackles multiple pain points in one architecture—location awareness, robust local representations, and flexible image resolution—without sacrificing the main vision-text alignment. This unified approach removes the need for separate models or excessive fine-tuning, allowing us to handle varied tasks like OCR, document processing, and general classification with minimal complexity. The training recipe also scales up neatly, ensuring that bigger models gain stronger fine-grained capabilities. By aligning visual and textual information more tightly, SigLIP 2 serves as a solid foundation for advanced Vision Language Models, reducing engineering overhead and enabling more powerful multimodal applications.
Why and How This Is Special
The model’s combination of global-local alignment, masked patch prediction, and dynamic resolution fine-tuning broadens its usability for tasks requiring detailed spatial reasoning, varied image shapes, and robust text alignment. This streamlined approach addresses real-world constraints like different aspect ratios while preserving strong overall accuracy.
📡 OpenAI rolls out its AI agent, Operator, in several countries

🎯 The Brief
OpenAI is expanding Operator, its AI agent, to ChatGPT Pro users in Australia, Brazil, Canada, India, Japan, Singapore, South Korea, the U.K., and more. The tool, originally launched in the U.S., can handle task automation like booking tickets, making reservations, filing reports, and online shopping.
⚙️ The Details
→ Operator is a standalone AI agent that executes real-world tasks for users. It is currently available only on the $200/month ChatGPT Pro plan.
→ Users must access Operator via a dedicated webpage where it runs in a separate browser window for task execution. Users can take control manually if needed.
→ It is not yet available in the EU, Switzerland, Norway, Liechtenstein, or Iceland.
→ Competitors include Google (waitlist-only project), Anthropic (API-based agent), and Rabbit (hardware-dependent action model). OpenAI’s approach makes it widely accessible compared to these alternatives.
🧠A 1B-param model can outmaneuver a 405B-param LLM in tough math tasks using test-time scaling (TTS)

Shanghai AI Lab shows that a properly tuned 1B SLM, with smart scaling, can outperform a 405B LLM on tough math tests.
Test-Time Scaling (TTS) Overview ⚙️
TTS applies extra compute cycles during inference. Internal TTS trains a model to generate a chain-of-thought. External TTS uses a policy model plus a process reward model (PRM) that rates the policy’s outputs. A simple setup is best-of-N, where multiple answers are generated, and the PRM picks the best. More advanced approaches include beam search and diverse verifier tree search, which break down the answer and refine it step by step.
Choosing the Right Approach 🔍
Efficiency depends on the size of the policy and PRM, plus the complexity of the problem. Smaller models benefit more from search-based methods, while larger models often perform best with best-of-N. For very small policies, best-of-N works well on simple tasks, but beam search excels at harder tasks. For mid-sized models, diverse verifier tree search handles easy and medium tasks, and beam search remains strong for harder ones.
Why Smaller Models Can Win 🚀
A carefully chosen TTS strategy can give a 3B-parameter model an edge over one with 405B parameters on benchmarks like MATH-500 and AIME24. With the right approach, a 500M-parameter Qwen2.5 can outperform GPT-4o. Training and inference efficiency also improve, as SLMs with TTS can achieve similar or better accuracy using significantly fewer floating-point operations.
Key Insight 🧩
TTS methods unlock reasoning capabilities that remain hidden in smaller models. Larger models see diminishing returns from TTS, but smaller ones gain substantial accuracy boosts at lower compute cost.
🛠️ Opinion - Now you can ingest fresh X (Tweets) data through Grok 3 and crafts authentic pieces blending live user opinions

X Connection in Action ⚙️
I tested Grok 3’s direct link to X, pulling current tweets from recognized accounts in seconds. For writers working on articles, newsletters, or any content, that instant access to fresh X data is invaluable. No stale information—just the latest updates as they happen.
Instead of scrolling feeds to find relevant takes, I watched Grok do the heavy lifting. It fetched timestamps and authors, which I then confirmed on X to catch any hallucinated posts. This swap from manual searching to assisted discovery felt like a streamlined assembly line for ideas.
Shaping Tone and Structure ✍️
I started with a detailed prompt defining the goal—an article referencing live user comments—and gave it a sample of my writing for style. Grok generated an outline, then fleshed out each section in small increments. Splitting the output kept the writing crisp and focused. The system picked up my informal tone and wove it into coherent paragraphs.
Verifying Speed and Accuracy ⚡
It became clear that speed was Grok’s main advantage. I typed my request, and the model delivered fresh X highlights almost instantly. The risk of inaccurate tweets still existed, but verifying them took a fraction of the usual time. The payoff was a richer article steeped in real-time user sentiment.
Pushing Content Boundaries 🎯
This blend of live data and AI-driven drafting refines how articles are produced. The entire process—outlining, retrieving tweets, fact-checking—happened smoothly. It took less effort to incorporate user reactions into my writing, and the final result felt more connected to the real conversation.
🗞️ Byte-Size Briefs
DeepSeek is set to open-source five code repositories next week, a rare move in an industry dominated by closed-source models. This initiative aims to promote transparency, democratize AI, and potentially undercut the value of proprietary AI models. Chinese universities are already integrating DeepSeek’s technologies into their curricula, signaling a shift towards open-source adoption in AI education.
vLLM v0.7.3 now supports DeepSeek's Multi-Token Prediction (MTP), delivering up to 69% speedup. Users can enable it with --num-speculative-tokens=1. The update also improves training efficiency and speculative decoding. DeepSeek enhancements include MLA (Multi-Level Attention) prefix caching, expert parallelism, and attention data parallelism coming soon. Other key updates include 17% latency reduction on AMD, FlashAttention3 for MLA, and pipeline parallelism.
That’s a wrap for today, see you all tomorrow.