


🧠 Tinyzero: Berkeley Researchers Reproduce Deepseek R1-Zero With Extreme Low-Cost
Reproduce Deepseek R1-Zero, 15x leaner vector search, DeepSeek challenges chip controls, OpenAI boosts app creation, and Qwen Chat v0.2 expands multimedia capabilities.
Read time: 7 min 32 seconds
📚 Browse past editions here.
( I write daily for my 112K+ AI-pro audience, with 4.5M+ weekly views. Noise-free, actionable, applied-AI developments only.
⚡In today’s Edition (25-Jan-2025):
🧠 Tinyzero: Berkeley Researchers Reproduce Deepseek R1-Zero With Extreme Low-Cost
🛠️ New Tool - Vector search on top of millions of docs in seconds. no pre-indexing - reducing model size by 15x and making the models up to 500x faster
🗞️ Byte-Size Briefs:
DeepSeek-R1 challenges U.S. dominance despite chip export controls.
OpenAI adds o1 to Canvas, enabling React/HTML app creation.
Qwen releases Chat v0.2: integrates search, video, image tools.
🧑🎓 Deep Dive Tutorial
Google DeepMind CEO Demis Hassabis discusses The Path To AGI And Says its 3-5 Years Away.
🧠 TinyZero: Reproduce DeepSeek R1-Zero for $30

🎯 The Brief
Jiayi Pan reproduced DeepSeek R1-Zero using RL on a 3B Qwen model for math tasks, costing under $30 to train. This shows smaller LLMs can gain self-verification and search skills via RL, making advanced AI research more accessible and cheaper. They applied it to CountDown: a game where players combine numbers with basic arithmetic to reach a target number. So not a general result at all, but a great proof of concept.
The most interesting part of this project is that, it demonstrates the eazy reproducibility of this, on a small-enough scale that a PhD student can reimplement it in 1-2 days with the cost of a lunch (less than $30).
⚙️ The Details
→ The reproduction of DeepSeek R1-Zero's capabilities was done with Countdown and multiplication tasks using a smaller 3B Qwen base model and Reinforcement Learning. This was achieved with a finetuning cost of less than $30.
→ The team utilized veRL framework and open-sourced their code as TinyZero on Github. Their experiments show that even a 1.5B model can learn search and self-verification, improving scores, while a 0.5B model struggles with reasoning.
→ Both base and instruct models work, with instruct models learning faster but reaching similar performance levels. Different RL algorithms like PPO, GRPO, and PRIME were tested and found to be effective. The project aims to democratize RL scaling research in LLMs.
The actual process
👶 Stage 1: Baby Steps (Dummy Outputs) - Initially, the model is kinda clueless. It's like a baby just babbling – spitting out random equations that probably don't make sense for the problem. Think of it as throwing darts in the dark.
🧠 Stage 2: Brain Training (Develop Tactics) - This is where Reinforcement Learning (RL) kicks in! Remember, RL is all about learning through trial and error and getting rewards. The model starts learning strategies. Crucially, it figures out "revision" (how to tweak its answers) and "search" (how to explore different equation possibilities). It's learning to aim those darts.
🎯 Stage 3: Aiming for Bullseye (Propose Solution) - Now, armed with its new tactics, the model actually tries to solve the problem. It proposes an equation, a potential answer. It's taking a shot at the bullseye.
🧐 Stage 4: "Hold On, Let Me Check..." (Self-Verify) - Here's the cool part: the model doesn't just blindly trust its first attempt. It self-verifies! It checks if its proposed equation actually works and gets to the target number. It's like checking if the dart actually hit the bullseye.
🔄 Stage 5: Try, Try Again (Iteratively Revise) - If the self-check fails (missed the bullseye!), the model goes back to revising. It tweaks the equation, searches for better combinations, and tries again. This loop repeats until it nails the correct answer! Practice makes perfect, even for LLMs!
Checkout their Github Repo for this project
You can learn quite a few things from this Github.
RL finetuning recipe for math reasoning in small LLMs (3B). Shows RL can imbue smaller models with complex skills.
VeRL framework is key here. Repo uses it for efficient RLHF pipeline, showcasing its flexibility for different algorithms (PPO, GRPO, PRIME).
Hybrid Engine (Actor + Rollout) design for efficiency. Crucial for low-cost training.
They have a detailed setup, data preprocessing, training scripts, ablation studies.
Demonstrates score improvements in Countdown game and ablations on model size and RL algos.
Modular design: Easy to extend to new models (FSDP, Megatron backends) and RL algorithms (DPO example).
🛠️ New Tool - Vector search on top of millions of docs in seconds. no pre-indexing - reducing model size by 15x and making the models up to 500x faster
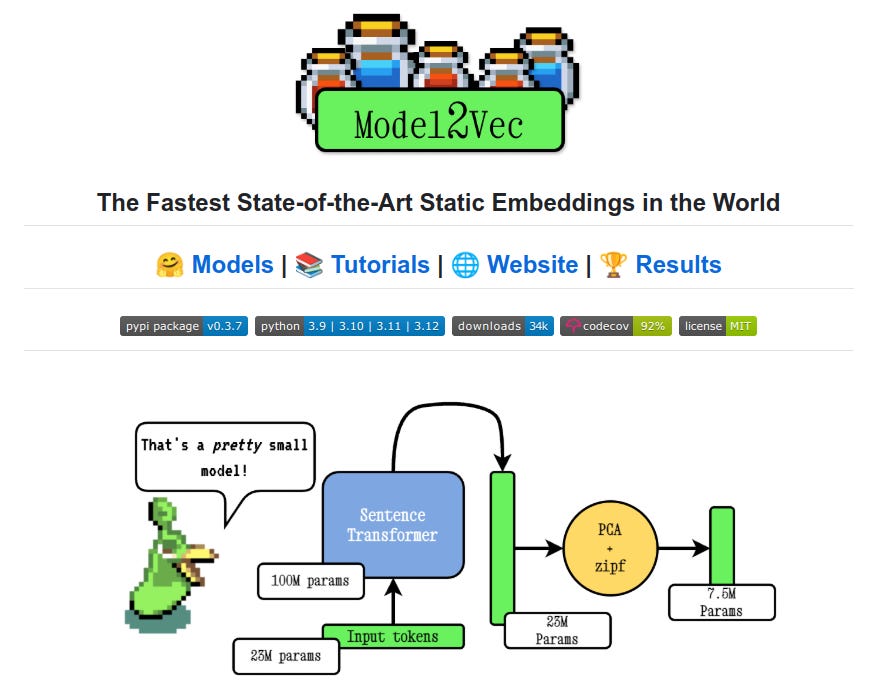
Embeddings on steroids: 15x smaller, 500x faster, zero effort.
Model2Vec is an embedding powerhouse that distils good models and makes them up by 500x faster and 15x smaller.
What Static Embeddings is all about
Static embeddings represent words, phrases, or sentences as fixed-size vectors where each input always maps to the same output, regardless of the context. Unlike contextual embeddings from models like BERT, static embeddings ignore surrounding text, making them lightweight and fast. Techniques like PCA and vocabulary weighting optimize these embeddings for specific tasks like search or clustering.
Instead of using large, complex models that process sentences to generate embeddings on the fly (like Sentence Transformers), static embeddings are pre-calculated for individual words or sub-word pieces in a vocabulary.
Think of it like this:
Traditional, dynamic embeddings (like Sentence Transformers): Imagine you have a recipe that you cook from scratch every time you want to eat. It's powerful and flexible, but takes time and resources.
Static Embeddings (like Model2Vec): Imagine having pre-made spice blends. They are much smaller, faster to use, and still give you a good flavor (text representation) for many dishes (tasks).
What this Github offers:
⚡ Instant vector search over millions of documents with no pre-indexing.
📉 Models shrunk by 15x in size and accelerated up to 500x, with minimal performance drop.
🧠 Easy-to-use distillation for creating static embedding models from Sentence Transformers in seconds.
🛠️ Pre-trained state-of-the-art static embedding models on HuggingFace.
🚀 Integrations with LangChain, Sentence Transformers, txtai, and more for seamless workflows.
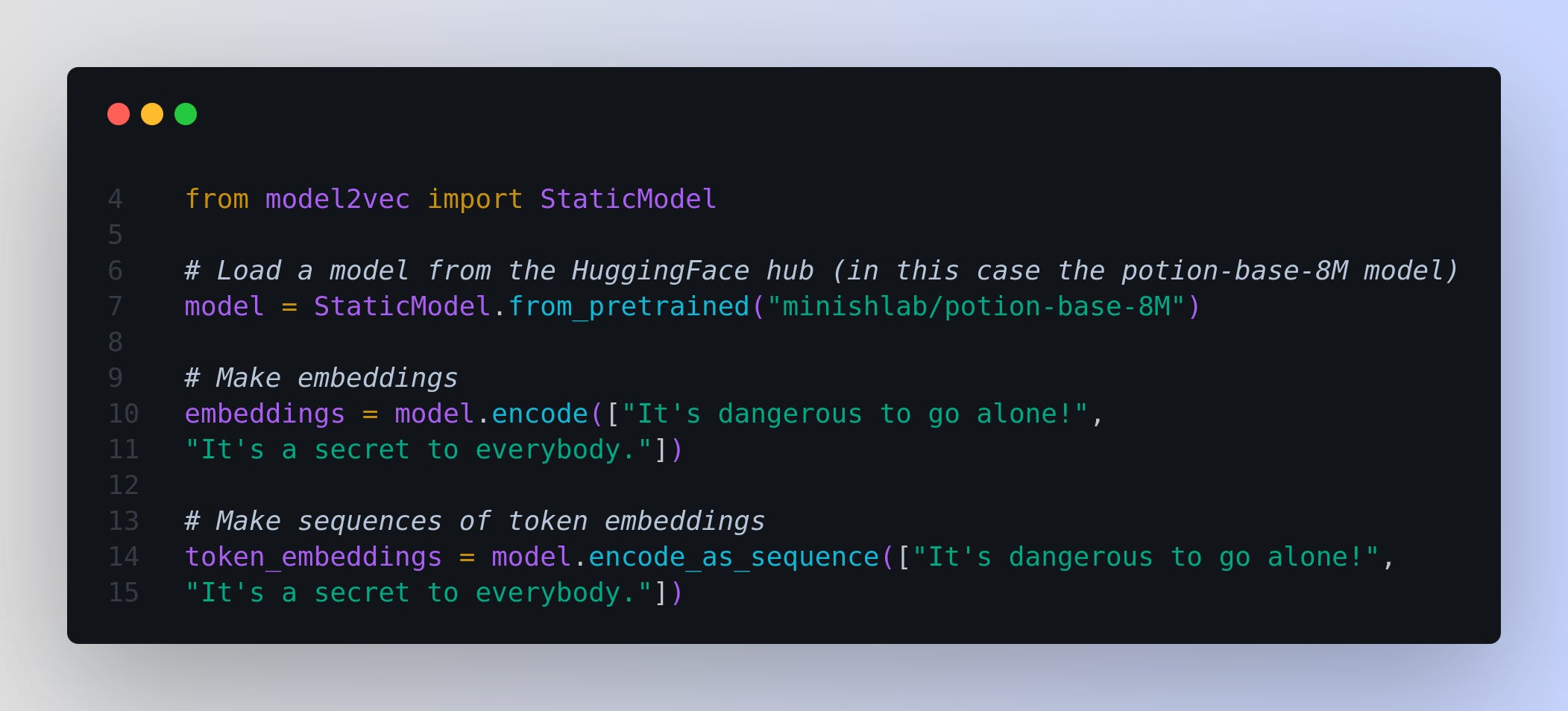
The easiest way to get started with Model2Vec is to load one of their flagship models from the HuggingFace hub. These models are pre-trained and ready to use. The following code snippet shows how to load a model and make embeddings:
🗞️ Byte-Size Briefs
The news around DeepSeek-R1 continues to make waves. CNBC published an article talking about how its threatening U.S. dominance. Specially given DeepSeek also had to navigate the strict semiconductor restrictions that the U.S. government has imposed on China, cutting the country off from access to the most powerful chips, like Nvidia’s H100s. The latest advancements suggest DeepSeek either found a way to work around the rules, or that the export controls were not the chokehold Washington intended. This is calling into question the utility of the hundreds of billions worth of capex being poured into this industry.
OpenAI added its o1 model to Canvas. You only need to select o1 from the model picker and use the toolbox icon or the “/canvas” command. With it Canvas can render HTML & React code. They have fully rolled out canvas on the ChatGPT desktop app for macOS to all tiers. Canvas with o1 is available to Pro, Plus, and Team users. React/HTML code rendering is available to Pro, Plus, Team, and Free users. Both updates will roll out to Enterprise and Edu in a couple weeks. Now anyone can almost build apps in a matter of hour. You can give it any image and it generates slides from it. The vision API generates an explanation and gpt-4o-mini summarizes those into content + title.
Qwen rolled out Qwen Chat v0.2. It integrates web search, video creation, and image generation into one platform. Alongside features like image understanding and document processing, it offers powerful tools for productivity and creativity, streamlining both professional tasks and personal projects effortlessly.
🧑🎓 Deep Dive
Google DeepMind CEO Demis Hassabis discusses The Path To AGI And Says its 3-5 Years Away

🎯 The Brief
Demis Hassabis, Google DeepMind CEO, discussed the progress and future of AGI, stating it's still a "handful of years away", likely 3-5 years. He cautioned against overhyped claims of AGI by 2025, suggesting they are probably just marketing. Current AI excels in niche tasks but lacks consistent reasoning, planning, and long-term memory for true AGI.
⚙️ Key Takeaways
→ Current models are strong in areas like math Olympiads but surprisingly weak in basic math and reasoning, showing inconsistency.
→ A key AGI benchmark is the ability to invent new hypotheses, not just solve existing problems.
→ AI hype is overestimated in the short-term but underestimated for its long-term impact.
→ Current AI products like Gemini 2.0 are useful for research and summarization but not yet pervasive in daily life.
→ Future AI, like Project Astra, aims for universal assistants integrated into all aspects of life.
→ Developing robust world models and incorporating planning and search from game AI are crucial steps.
→ Deception is an emerging concern, requiring safety measures like secure sandboxes.
→ While scaling current models helps, it's not sufficient for AGI; new techniques are needed.
→ Hassabis envisions a future web with agents negotiating with each other, and AI revolutionizing fields like drug discovery and materials science.