


🥉 OpenAI starts to show o3-mini’s reasoning summary and chain of thought display
[The above podcast on today’s post was generated with Google’s Illuminate]

Read time: 9 min 27 seconds
📚 Browse past editions here.
( I write daily for my 112K+ AI-pro audience, with 4.5M+ weekly views. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (7-Feb-2025):
🥉 OpenAI updates o3-mini’s communication, will support transparent reasoning and chain of thought display
🏆 GitHub Copilot also jumps on the Agentic AI train
🧑🎓 Deep Dive Tutorial
📡 Unsloth’s showcased a notebook converting a standard LLM into an R1 reasoning model using GRPO
🥉 OpenAI updates o3-mini’s communication, will support transparent reasoning and chain of thought display
🎯 The Brief
OpenAI has updated its o3-mini AI model to provide users with more detailed reasoning summaries, enhancing transparency in its decision-making process. This move is influenced by growing competition, especially from DeepSeek’s R1 model, which offers full reasoning steps. While OpenAI still doesn’t expose the full reasoning chain, the update improves clarity, trust, and accessibility for users while protecting proprietary IP. The model now filters unsafe content and translates reasoning into users' native languages.
⚙️ The Details
→ Users of ChatGPT, both free and paid, will now see more detailed "chain of thought" summaries from the o3-mini model. This applies especially to premium users using the "high reasoning" mode.
→ Unlike DeepSeek's R1 model, which fully reveals its thought process, OpenAI balances transparency with competitive secrecy. Previously, OpenAI's models only provided summaries of reasoning steps, which were sometimes inaccurate.
→ The updated model reviews its reasoning chain, removes unsafe content, and then simplifies complex concepts before presenting them to users. Non-English users benefit from an added translation step, making AI-generated reasoning more accessible globally.
→ Critics argue that withholding full reasoning steps limits AI accountability, but OpenAI maintains that full transparency could lead to competitive distillation.
→ OpenAI's incremental transparency strategy aims to retain user trust while protecting proprietary technology in the race against DeepSeek and other AI competitors.
🏆 GitHub Copilot also jumps on the Agentic AI train

GitHub has introduced Agent Mode in Copilot, allowing autonomous coding assistance in VS Code. This mode enables Copilot to infer subtasks, self-correct errors, and make multi-file edits. Additionally, Copilot Edits is now generally available (GA) in VS Code, enhancing multi-file inline editing with GPT-4o, Claude 3.5 Sonnet, and Gemini 2.0 Flash. Lastly, Project Padawan, an upcoming SWE agent, will automate issue resolution by generating fully-tested pull requests. These advancements aim to elevate Copilot from an AI assistant to an autonomous coding peer.
⚙️ The Details
→ Agent Mode, now in preview, allows Copilot to iterate on its own code, fix errors, suggest terminal commands, and analyze runtime issues autonomously. It can now infer missing subtasks and automatically resolve issues, reducing manual intervention.
→ Copilot Edits, now GA, supports multi-file inline editing via natural language prompts. Users can choose between OpenAI’s GPT-4o, o1, o3-mini, Anthropic’s Claude 3.5 Sonnet, and Google’s Gemini 2.0 Flash. The system leverages speculative decoding for faster, context-aware edits.
→ Project Padawan, GitHub’s upcoming SWE agent, will allow users to assign issues directly to Copilot. It will autonomously generate pull requests, run tests, lint code, and integrate feedback, simulating a real developer contributing to repositories.
→ Copilot’s automation pipeline includes secure sandboxing, environment setup, repository cloning, and context-aware decision-making to ensure code quality and project adherence.
→ Future plans include improving speculative decoding, integrating edits into chat workflows, and refining undo capabilities.
🧑🎓 Deep Dive Tutorial
📡 Unsloth’s showcased a notebook converting a standard LLM into an R1 reasoning model using GRPO

Their new GRPO uses 80% less VRAM than Hugging Face + FA2, allowing you to reproduce R1-Zero's "aha moment" on just 7GB of VRAM using Qwen2.5 (1.5B).
Checkout the GRPO Notebook here.
The notebook shows how to use Unsloth’s GRPO method to enable a language model (for example, Llama 3.1 8B Instruct) to develop its own chain-of-thought reasoning. Instead of needing pre-collected chain-of-thought data, GRPO uses reinforcement learning with custom reward functions to encourage the model to generate internal reasoning traces. This approach allows you to convert any standard model (up to around 15B parameters) into a reasoning model with far less VRAM than traditional methods.
That sounds almost impossible right? Let’s understand it from ground-up.
What is GRPO? GRPO stands for Group Relative Policy Optimization. In traditional reinforcement learning (RL), a policy (in this case, your language model) is adjusted by comparing its generated outputs against a baseline—usually provided by a value function or an external reward. GRPO, instead, works by taking a group of generated responses and comparing each individual response’s performance against the group’s average. This “relative” comparison produces an advantage signal that tells the model which responses are better than others, without the need for a separately learned value function. In simple terms, if one response in a batch is better than most, it gets a positive push, while poorer responses are nudged down.
How Does GRPO Enable Reasoning? A standard LLM, when prompted with a question, might simply generate an answer without showing its internal thought process. However, if you structure the expected output—for example, by specifying a format with a dedicated section for chain-of-thought reasoning—the model initially may not follow this pattern consistently. With GRPO, you do the following:
Multiple Completions: For a given prompt (which instructs the model to output both its reasoning and the final answer), the model generates a group of responses. Each of these responses includes an internal “chain-of-thought” section and the final answer.
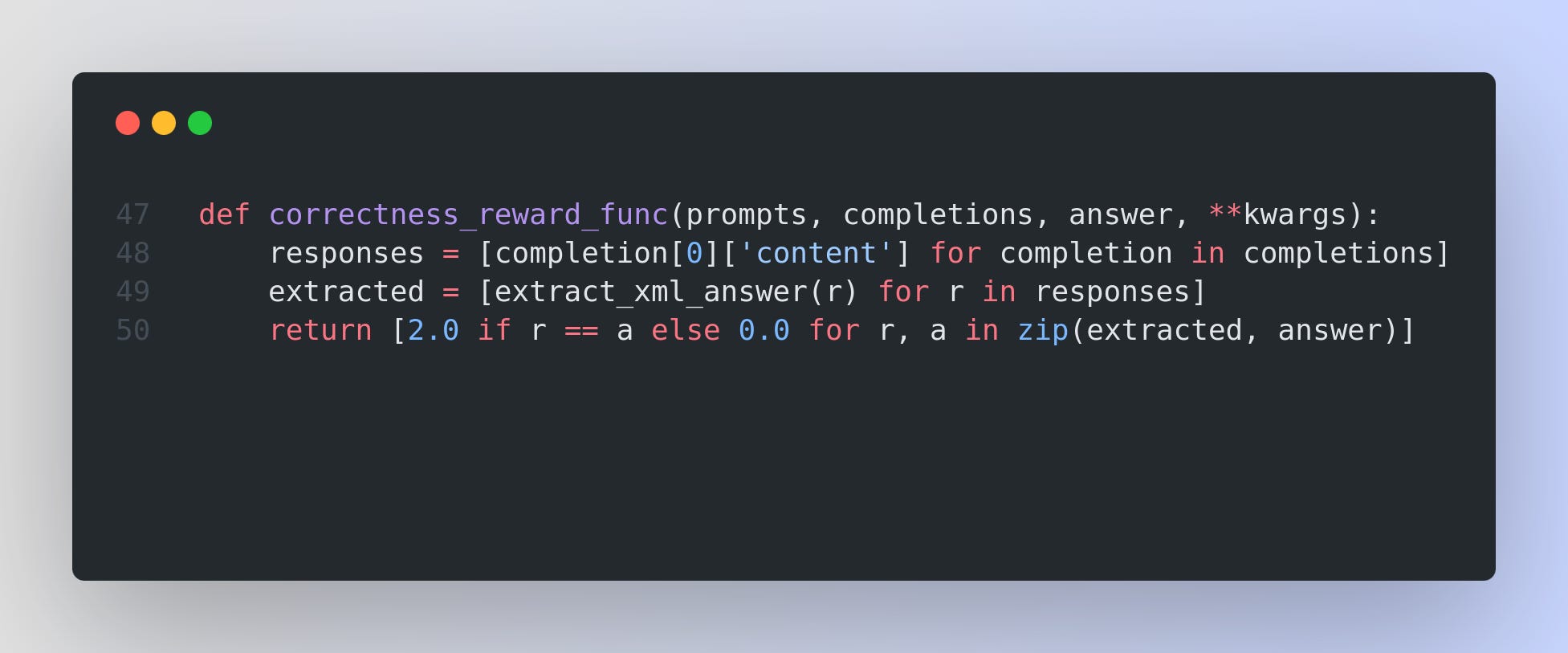
Reward Functions: Custom reward functions are defined to evaluate each response. These functions can measure whether the reasoning is present (and follows a specific format), whether the final answer is correct, or whether intermediate steps are logically coherent. For example, one reward function might add a score if the reasoning section is formatted correctly or if the numerical answer matches the expected result.
Relative Comparison: Once the responses are scored individually, GRPO computes the average score for the group. Each response’s performance is then evaluated relative to this average. If a response scores higher than the group average, the model receives a positive signal to generate similar outputs in the future.
Policy Update: Using these relative rewards, the model is fine-tuned via policy gradients. The optimization process nudges the model’s parameters so that future completions are more likely to produce a well-structured chain-of-thought along with the correct final answer. In other words, the model learns to “think” internally before providing the answer.
Converting a Standard LLM into an R1 Reasoning Model The key idea is that you don’t have to change the underlying architecture of the LLM; you only fine-tune it. Here’s how the conversion works in practice:
Structured Prompts: The process starts by modifying the prompt format. You ask the model to output its reasoning in a dedicated block (for example, wrapped in
<reasoning>...</reasoning>) followed by the final answer (e.g.,<answer>...</answer>). This teaches the model what “reasoning output” should look like.SYSTEM_PROMPT = """\ Respond in the following format: <reasoning> ... </reasoning> <answer> ... </answer> """Later, thIS SYSTEM_PROMPT is integrated into the dataset creation. For example, in the get_gsm8k_questions function, the prompt is used to wrap each question:
def get_gsm8k_questions(split="train"): data = load_dataset('openai/gsm8k', 'main')[split] data = data.map(lambda x: { 'prompt': [ {'role': 'system', 'content': SYSTEM_PROMPT}, {'role': 'user', 'content': x['question']} ], 'answer': extract_hash_answer(x['answer']) }) return dataFine-Tuning with GRPO: During fine-tuning, the model is presented with training examples where it is expected to generate this two-part output. GRPO is applied during training, meaning that for each input, the model generates several completions. Reward functions check the presence and quality of the chain-of-thought, as well as the correctness of the final answer.
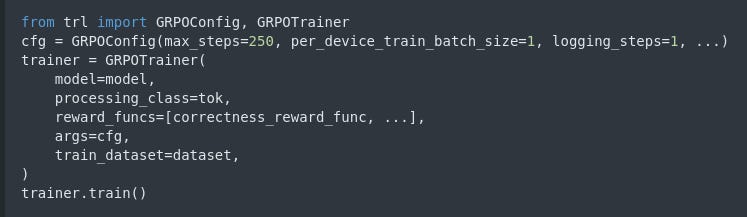
from trl import GRPOConfig, GRPOTrainer training_args = GRPOConfig( learning_rate=5e-6, per_device_train_batch_size=1, max_steps=250, logging_steps=1, # ... other hyperparameters as needed ) trainer = GRPOTrainer( model=model, processing_class=tokenizer, reward_funcs=[ xmlcount_reward_func, soft_format_reward_func, strict_format_reward_func, int_reward_func, correctness_reward_func, ], args=training_args, train_dataset=dataset, ) trainer.train()Reinforcement of the "Aha Moment": Early in training, the model might not show any internal reasoning. However, as GRPO’s relative rewards start favoring responses that include a well-developed chain-of-thought, the model begins to adjust. This is the “aha moment” where it autonomously learns to allocate more “thinking time”—or internal processing—to produce its reasoning, leading to more accurate answers.
Outcome: After sufficient training, the model effectively transforms its behavior. It now consistently produces a reasoning trace before arriving at its final answer. This fine-tuning process converts a “vanilla” LLM into what is called an R1 reasoning model—a model that self-verifies and provides clear internal reasoning steps without needing explicit chain-of-thought training data.
Why Is This Possible? The power of GRPO lies in its ability to use relative rewards from a group of responses to overcome some of the high variance issues in standard RL methods. Instead of relying on an external critic (a value function), the algorithm creates its own baseline from the responses themselves. This means that even if a model was not originally designed to “think aloud,” it can learn to do so when the reinforcement signal directly favors detailed reasoning. The approach has been shown (in research like DeepSeek’s R1 experiments) to be effective even when using modest hardware resources—making it a practical method for converting standard LLMs into reasoning models.
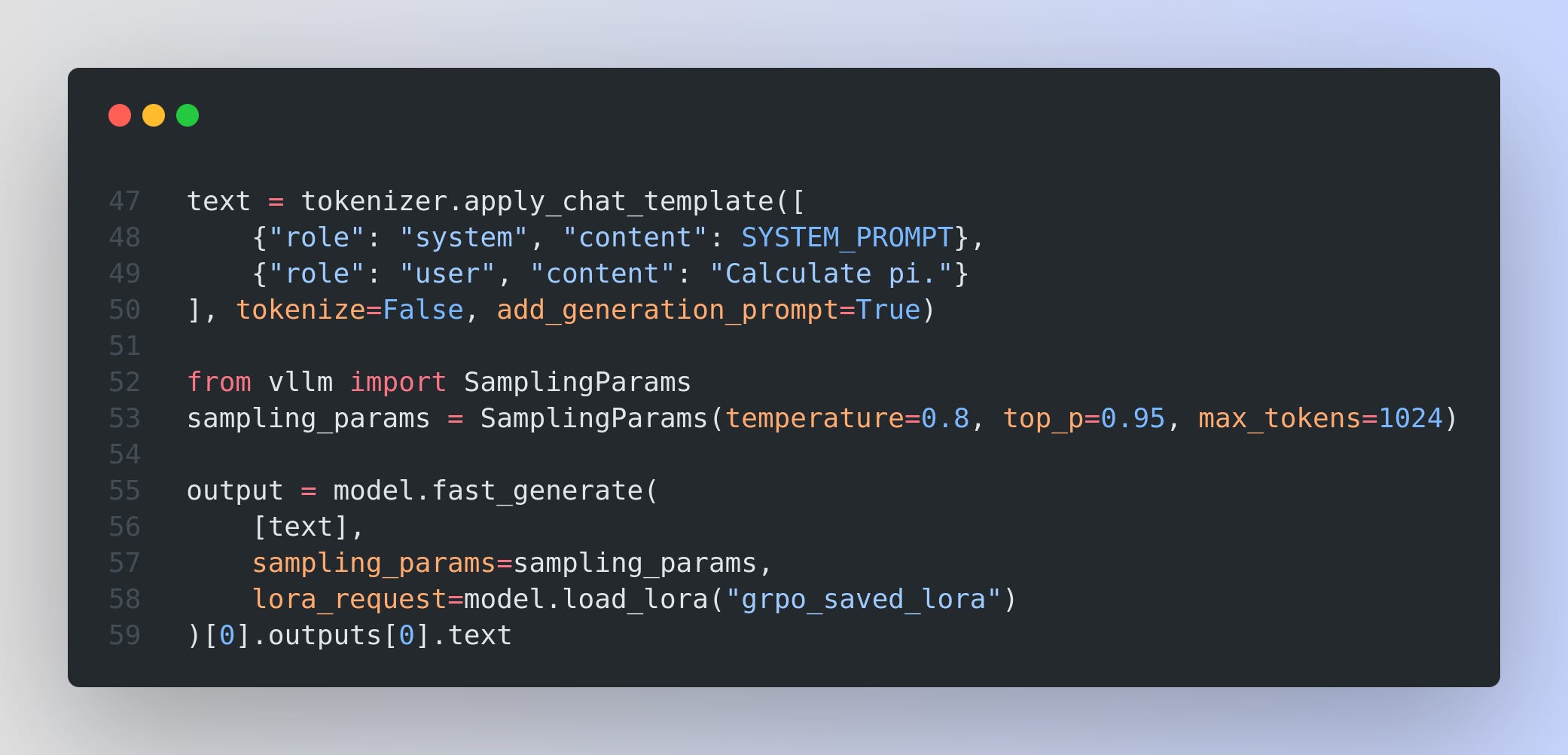
Setup and Dependencies Unsloth requires its own library along with fast inference support from vLLM. In addition, a patched version of the TRL library is used so that GRPO works seamlessly with LoRA and QLoRA fine-tuning. For example, the installation commands are as simple as:

A key function, PatchFastRL, is then used to patch the GRPO-related functions into Unsloth’s fast model interface.
Model Initialization and LoRA Integration Next, the notebook loads a base model and applies LoRA adapters so that GRPO training can be performed efficiently. The model is loaded in a memory-efficient 4-bit mode and with fast inference enabled. For example:
from unsloth import FastLanguageModel, PatchFastRL
PatchFastRL("GRPO", FastLanguageModel)
model, tok = FastLanguageModel.from_pretrained(
model_name="meta-llama/meta-Llama-3.1-8B-Instruct",
max_seq_length=512,
load_in_4bit=True,
fast_inference=True,
max_lora_rank=32,
gpu_memory_utilization=0.6,
)After loading, a LoRA adapter is attached to select modules (such as the projection layers) to allow fine-tuning with GRPO. This setup is essential because it reduces the memory footprint and speeds up training.
Data Preparation and Reward Functions For training data, the notebook leverages the GSM8K dataset. The questions are formatted to include a system prompt that instructs the model on the expected output format (with dedicated sections for reasoning and the final answer).
Several reward functions are defined to guide the reinforcement learning process. These functions assess the generated outputs based on criteria like correct arithmetic answers, adherence to a specific XML-like format, or even a simple count of expected tokens. One minimal example is:

This function (along with others such as soft/strict format check and integer reward functions) is passed into the trainer to drive the model’s “aha moment” behavior. training the Model with GRPO Training is managed by the GRPOTrainer class from TRL.
That’s a wrap for today, see you all tomorrow.
Thanks for that deep dive in GRPO, very timely and clear