


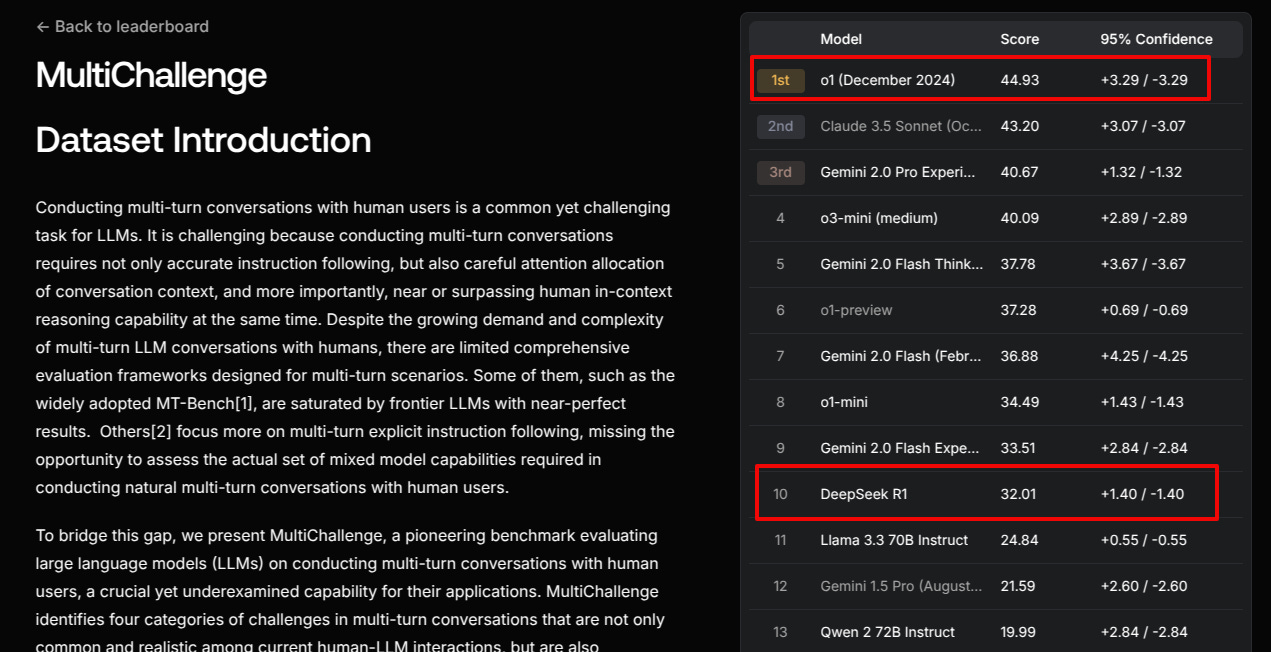
🥉 MultiChallenge, a new multi-turn conversation benchmark is released and DeepSeek-R1 ranked way down at the 10th position
OpenAI’s Deep Research vs. Google, ChatGPT search for all, MultiChallenge rankings drop DeepSeek-R1 to 10th, Gemini 2.0 Flash scores 83 AAQI, and Hugging Face adds Spaces search.
[The above podcast on today’s post was generated with Google’s Illuminate]
Read time: 9 min 10 seconds
📚 Browse past editions here.
( I write daily for my 112K+ AI-pro audience, with 4.5M+ weekly views. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (6-Feb-2025):
🥉 MultiChallenge, a new multi-turn conversation benchmark is released and DeepSeek-R1 ranked way down at the 10th position
🏆 Can OpenAI’s Deep Research automate the work of research assistants - a study compares OpenAI and Google Deep Research
🌐 ChatGPT search is now available to all users, even those without an account. So now it is just like Google
🛠️ NVIDIA AI Project teaches robots to move like athletes
🥊 Open rival to OpenAI’s o1 ‘reasoning’ model for under $50
🗞️ Byte-Size Briefs:
Hugging Face now has a Spaces search feature, making it easier to find AI apps (e.g., image-to-3D, transcription).
Gemini 2.0 Flash scores 83 on the AAQI and matches Gemini 1.5 Flash's speed, priced at $0.1/$0.4 per million tokens.
Alma, an AI-powered nutrition app, lets users track food via speech, text, or photos, costing $19/month or $199/year.
Perplexity & You.com now host DeepSeek R1 in the US/EU, addressing privacy concerns while keeping some censorship.
LinkedIn is testing an AI-driven job search tool that suggests roles based on deep analysis rather than just keywords.
DeepSeek bans are growing, with South Korea joining eight other countries restricting its use
🥉 MultiChallenge, a new multi-turn conversation benchmark is released and DeepSeek-R1 ranked way down at the 10th position
🎯 The Brief
Scale AI introduces MultiChallenge, a new benchmark for evaluating LLMs on multi-turn conversations. This is significant because existing benchmarks are saturated, with top LLMs scoring near-perfect. MultiChallenge tests instruction retention, inference memory, versioned editing, and self-coherence. The top model, Claude 3.5 Sonnet, only scores 41.4%.
⚙️ The Details
→ MultiChallenge addresses the gap in evaluating LLMs in realistic multi-turn conversations, where current LLMs struggle, despite excelling in existing single-turn or simple multi-turn evaluations.
→ The benchmark focuses on four key challenge areas: retaining instructions across turns, inferring information from user context, handling edits across versions, and maintaining consistency.
→ Data was created with a hybrid approach that used AI-generated conversations that was reviewed and edited by human experts. This process ensured high quality, realistic, and challenging test examples that could actually make the LLMs fail.
→ The research identified common failure cases that were confirmed and curated with the new automatic evaluation method that agrees with expert human raters.
→ An LLM-as-judge system with instance-level rubrics was developed for evaluation, achieving a 93% alignment with expert human raters, in stark contrast with only 36% for existing method.
🏆 Can OpenAI’s Deep Research automate the work of research assistants - a study compares OpenAI and Google Deep Research
🎯 The Brief
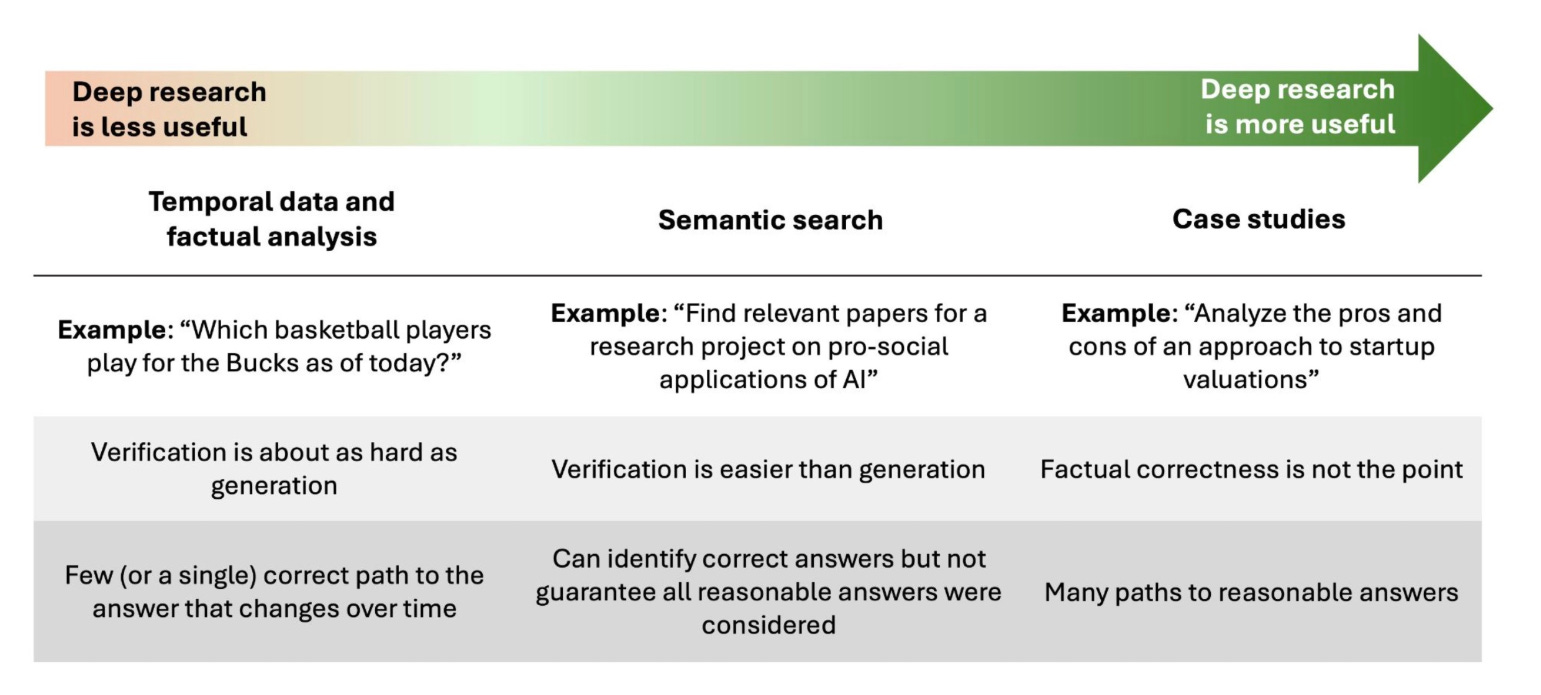
A viral tweetr post by a Princeton researchers tested OpenAI's o1-pro with Deep Research against Google’s Gemini 1.5-pro for research assistance. OpenAI’s model outperformed Gemini in understanding queries and producing useful reports in under 10 minutes, whereas Gemini required 10 iterations to reach comparable results. However, Gemini was 10x cheaper and integrated with Google Sheets, while OpenAI required manual CSV handling. The study highlighted Deep Research’s strengths in semantic search but its limitations in factual accuracy for real-time data.
⚙️ The Details
→ Deep Research automates web-based research, generating reports by retrieving information from online sources. OpenAI’s o1-pro understood complex queries quickly, provided clarifications, and produced a list of relevant examples with minimal iteration.
→ Experts debate Deep Research’s utility due to its varying performance across tasks. It struggles with factual queries requiring real-time accuracy, such as NBA player statistics.
→ For semantic search, Deep Research excels, helping to filter and shortlist relevant examples from massive datasets, reducing research time.
→ Compared to task-specific tools like Elicit, Deep Research provides broader search coverage (news, articles, academic papers) but lacks precise citations and structured output.
→ Final verdict: Deep Research is great for exploratory research and semantic search, but unreliable for fact-based or real-time queries.
🌐 ChatGPT search is now available to all users, even those without an account. So now it is just like Google

🎯 The Brief
OpenAI has made ChatGPT’s web search free for all users on ChatGPT.com, removing the need for a login. Previously, this feature was exclusive to ChatGPT Plus subscribers. This move challenges Google and Bing, offering real-time data (news, sports scores, weather) with no ads or paywalls. However, mobile app users still require login for access. This shift positions OpenAI as a direct competitor to traditional search engines and aligns with growing AI-powered search trends.
⚙️ The Details
→ ChatGPT’s web search is now free on desktop. Users can access real-time information without logging in, unlike before when it was locked behind a paywall.
→ Mobile apps still require login. OpenAI retains a tiered model, maintaining premium incentives for mobile users.
→ Direct competition with Google & Bing. By providing a conversational, ad-free search, OpenAI intensifies the AI-driven search race. This decision could drive mass adoption, pulling users away from traditional search engines.
→ Potential regulatory impact. AI search transparency and misinformation concerns may attract scrutiny from regulators like the EU.
🛠️ NVIDIA AI Project teaches robots to move like athletes

🎯 The Brief
Carnegie Mellon University and NVIDIA introduced ASAP, a two-stage framework enabling humanoid robots to move with agility similar to elite athletes. ASAP bridges the simulation-to-real-world gap by using a delta action model, correcting dynamic mismatches and significantly improving motion tracking accuracy. It was successfully tested on the Unitree G1 humanoid robot, demonstrating smooth, dynamic whole-body movements.
⚙️ The Details
→ ASAP enhances humanoid robot agility by refining control policies with real-world corrections, rather than relying on static system identification or domain randomization.
→ The delta action model in ASAP adjusts for physics mismatches in real-time, ensuring natural and expressive movements without overly conservative policies.
→ The framework fine-tunes pre-trained reinforcement learning policies, significantly reducing errors in transferring simulated skills to the real world.
→ Unlike traditional rigid physics approximations, ASAP treats simulation as a continuously evolving model, leveraging deep learning to iteratively correct discrepancies.
→ The approach allows humanoid robots to execute complex tasks like agile jumps and sports gestures, overcoming traditional sim-to-real limitations.
→ ASAP transforms real-world deployment noise into a supervised correction process, refining simulation iteratively for smoother execution. The framework reduced motion errors by 53% compared to existing methods — a major advance in bridging the gap between virtual and physical training.
🥊 Open rival to OpenAI’s o1 ‘reasoning’ model for under $50
🎯 The Brief
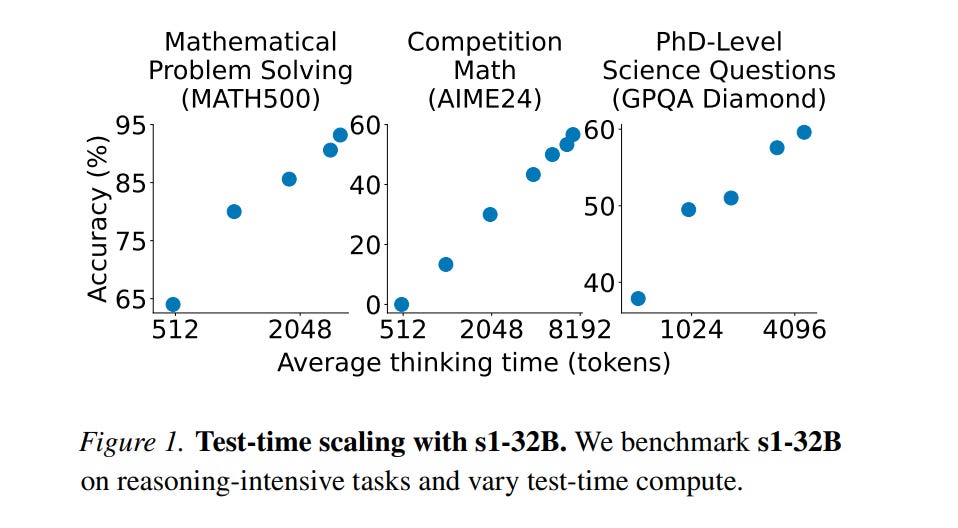
Stanford and the University of Washington researchers trained a reasoning AI model, s1, for under $50, rivaling OpenAI’s o1 and DeepSeek’s R1 in math and coding tasks. s1 was fine-tuned from Alibaba’s Qwen2.5-32B model using a small dataset (1,000 curated reasoning questions) and trained in under 30 minutes on 16 Nvidia H100 GPUs. Unlike costly reinforcement learning, they used supervised fine-tuning (SFT) and “budget forcing”—a technique that extends test-time computation. s1 outperforms OpenAI’s o1-preview on competition math benchmarks and is fully open-source on GitHub.
⚙️ The Details
→ s1 is distilled from Google’s Gemini 2.0 Flash Thinking Experimental, using its answers and reasoning traces. The researchers bypassed Google’s rate limits, but Google's terms prohibit reverse-engineering.
→ The budget forcing technique lets s1 extend its reasoning by adding “Wait,” forcing re-evaluation and improving accuracy.
→ s1 achieved up to 27% better performance than o1-preview on math benchmarks like AIME24 and MATH500.
→ DeepSeek’s R1 used reinforcement learning on 800K samples, whereas s1 achieved similar reasoning power with just 1,000 samples.
→ Training s1 cost around $20 in cloud compute, a fraction of the millions spent on proprietary models.
🍎 Mistral releases its AI assistant on iOS and Android
🎯 The Brief
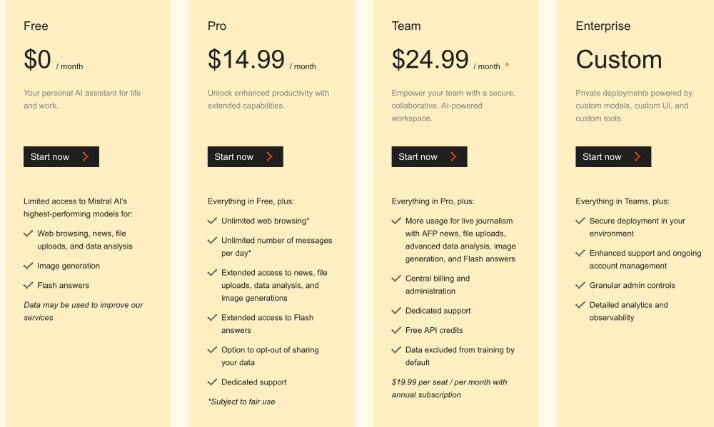
Mistral has launched a mobile app for its AI assistant, Le Chat, on iOS and Android, expanding beyond its web platform. The assistant competes with ChatGPT, Claude, Gemini, and Copilot while offering a Pro tier ($14.99/month) with better model access and data privacy options. Mistral claims Le Chat delivers up to 1,000 words per second with top-tier inference speed. The assistant also integrates Black Forest Labs’ Flux Ultra for enhanced image generation and supports enterprise deployments, a feature absent in ChatGPT and Claude Enterprise.
⚙️ The Details
→ Le Chat’s mobile app provides a simple chatbot interface for text-based interactions but lacks a voice mode. Enterprise users can deploy Le Chat on-premise with custom models, a crucial feature for industries like banking and defense.
→ Performance-wise, Le Chat claims to run on the fastest inference engines, capable of processing 1,000 words per second. For image generation, Le Chat outperforms ChatGPT and Grok by leveraging Black Forest Labs’ Flux Ultra.
→ Mistral has partnered with AFP to improve search results with verified news sources.
🗞️ Byte-Size Briefs
Hugging Face has launched a new Spaces search feature, allowing users to explore over 400,000 AI apps intuitively. This update enhances discovery across diverse AI-powered tools, from background removal to image-to-3D conversion, sound transcription, and virtual try-on.
Artificial Analysis report for Gemini 2 is out and Gemini 2.0 Flash scored 83 in the Artificial Analysis Quality Index, outperforming its experimental version by 1 point and beating Gemini 1.5 Pro’s score of 80. Its speed clocks in at 163 output tokens/s, matching Gemini 1.5 Flash. So Gemini 2.0 Flash is now an incredibly powerful model priced at just $0.1/$0.4 per million input/output tokens.
AI-powered nutrition app for iOS launches. The app simplifies calorie tracking by allowing users to talk, type, or take photos of their meals instead of manually logging them. It also provides personalized meal recommendations, a daily nutrition score, and dietary insights based on AI analysis. Alma is subscription-based, costing $19 per month or $199 annually. The startup has raised $2.9M from Menlo Ventures and Anthropic.
Perplexity and You.com now offer access to DeepSeek R1 without sending user data to China, addressing major privacy concerns. Perplexity hosts R1 in US/EU data centers, offering free users three Pro-level queries per day and unlimited access for $20/month. You.com provides R1 via its Pro plan ($15/month, discounted from $20), ensuring the model remains within the US. While Perplexity partially removes censorship, R1 still refuses to answer sensitive topics, even when tested.
LinkedIn is testing a new AI-powered job search tool that leverages a custom LLM to improve job recommendations. Unlike traditional keyword-based searches, this tool analyzes job descriptions, company insights, and industry trends to suggest roles that users might not have considered. The system also identifies skill gaps and suggests learning paths. This could transform job hunting but raises concerns over bias in AI-driven hiring.
Globally Government ban wave on DeepSeek usage increasing. South Korea just joined seven other countries in banning DeepSeek. Other countries enforcing bans include Australia, India, Taiwan, Italy, the US, Belgium, France, and Ireland.
That’s a wrap for today, see you all tomorrow.