


🪟 Microsoft Announces Largest-Ever AI Infrastructure Investment
Microsoft's biggest AI infrastructure investment push, ByteDance's FLUX compression breakthrough, new models from Rubik's AI, Olmo 2 Tech report, and brain-LLM processing parallels.

Read time: 7 min 10 seconds
⚡In today’s Edition (4-Jan-2025):
🪟 Microsoft Plans To Invest An Insane $80 Billion On Ai-Enabled Data Centers In Fiscal 2025
🔥 ByteDance Revolutionizes Image Generation with 1.58-bit FLUX, shrinks AI image generator to just three simple values {-1, 0, +1}, cuts storage by 7.7x
📡 Rubik’s AI releases Sonus-1 first model family of 2025
🛠️ Chinese Robotics Company Just Released Agibot World Alpha, One Of The Largest Open-Source Dataset For Humanoid Robot Training
🧠 Olmo 2 Released Their Tech Report , Reveals The Engineering Secrets And Training Detail For One Of The Few Remaining Frontier Fully Open Models
🗞️ Byte-Size Brief:
xAI announces Grok 3 pre-training completion using 100,000 H100 GPUs, 10x of that used for Grok-2
Researchers reveal LLMs mirror brain hierarchy patterns during language processing
🧑🎓 Deep Dive Tutorial
📚 Why the deep learning boom caught almost everyone by surprise
🪟 Microsoft Plans To Invest An Insane $80 Billion On Ai-Enabled Data Centers In Fiscal 2025

🎯 The Brief
→ Microsoft's $80 billion AI data center investment represents unprecedented scale in tech history, exceeding the annual R&D budgets of major tech companies and matching the GDP of numerous nations. No single company has ever directed this much capital toward such a concentrated technological bet. To put it in perspective, the Manhattan Project (which developed the atomic bomb) cost only $50 billion when adjusted for inflation.
⚙️ The Details
→ The scale is staggering - this investment surpasses Google's total R&D spend of $40 billion in 2022, essentially doubling typical tech industry investment patterns for AI infrastructure alone
→ For historical perspective, this single-year investment represents nearly 30% of the entire inflation-adjusted Apollo program cost of $280 billion, which was spread across a decade
→ The financial commitment equals almost half of Microsoft's existing Property, Plant and Equipment value of $153 billion, demonstrating extraordinary confidence in AI's future. Financial metrics show strong commitment - Q1 fiscal 2025 saw $20 billion in capital spending, marking a 5.3% increase.
→ The investment magnitude rivals the combined annual capital expenditure of the top five international oil companies at $88 billion, marking a historic shift in corporate infrastructure spending priorities
→ The $80 billion investment represents a massive leap from Microsoft's previous spending patterns. It represents one of the largest concentrated technological bets by any company in history.
→ This $80 billion commitment represents one of the largest single-year capital investments in corporate history, surpassing traditional capital-intensive industries like oil and gas, and demonstrating the extraordinary scale of infrastructure required for the AI revolution.
🔥 ByteDance Revolutionizes Image Generation with 1.58-bit FLUX, shrinks AI image generator to just three simple values {-1, 0, +1}, cuts storage by 7.7x
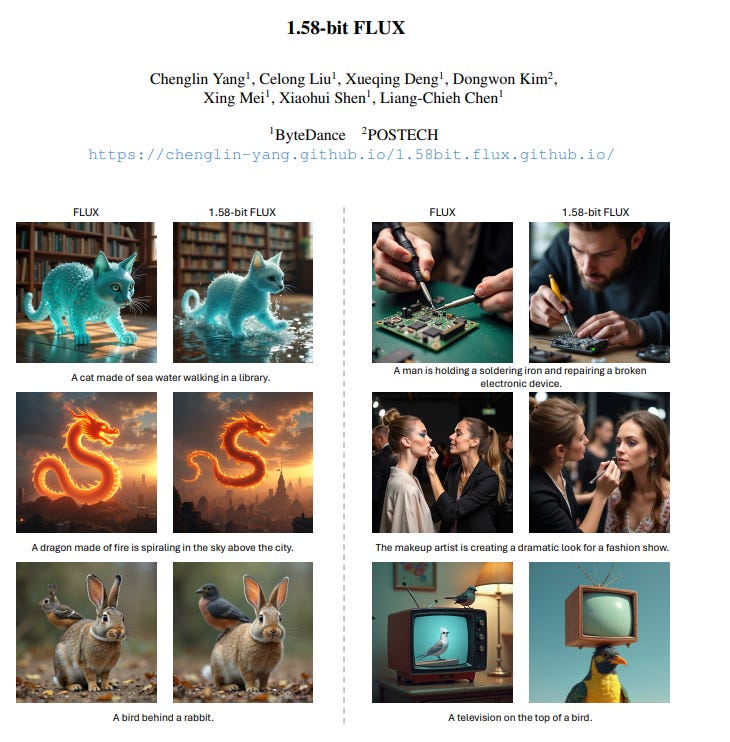
🎯 The Brief
ByteDance researchers introduced 1.58-bit FLUX, a breakthrough compression technique that reduces AI image generation model size by 7.7x while maintaining output quality, enabling efficient deployment on resource-constrained devices.
⚙️ The Details
→ The core innovation lies in quantizing 99.5% of FLUX vision transformer parameters (11.9B total) to just three values: +1, 0, -1, using self-supervision without requiring access to image data. The team developed a custom kernel optimized for low-bit computation.
→ The compression achieves significant efficiency gains: 7.7x reduction in model storage and 5.1x decrease in inference memory usage across various GPU types. Performance improvements are particularly notable on deployment-friendly GPUs like L20 (13.2% speedup) and A10.
→ Testing on industry benchmarks GenEval and T2I CompBench demonstrates comparable image generation quality to the full-precision model. Current limitations include slight degradation in fine detail rendering at very high resolutions and limited speed improvements without activation quantization.
📡 Rubik’s AI releases Sonus-1 first model family of 2025

🎯 The Brief
Rubik's AI launches Sonus-1 model family featuring four distinct variants with SOTA-competitive performance across language, reasoning, and code generation tasks, marking a significant entry in the LLM space with 90.15% MMLU and 97% GSM-8K benchmark scores. The performance rivals top competitors.
⚙️ The Details
→ The Sonus-1 family comprises four specialized variants: Mini (optimized for speed), Air (general use), Pro (complex tasks), and Reasoning (advanced problem-solving). Each variant demonstrates distinct performance characteristics across benchmarks.
→ Sonus-1 Reasoning showcases strong mathematical capabilities with 97% on GSM-8k and 91.8% on MATH-500. The model achieves 91% on HumanEval and 72.6% on Aider-Edit, demonstrating strong code generation abilities.
→ The system integrates real-time search functionality and Flux image generation capabilities, enabling dynamic information retrieval and visual content creation within the platform.
→ Notable performance metrics include Pro variant reaching 87.5% on MMLU (increasing to 90.15% with Reasoning), and 71.8% on MMLU-Pro. The Reasoning variant excels with 88.9% on DROP and 67.3% on GPQA-Diamond. I have to add that this results are coming from a relatively unknown company, so take these benchmarks with a grain of salt for now.
🛠️ Chinese Robotics Company Just Released Agibot World Alpha, One Of The Largest Open-Source Dataset For Humanoid Robot Training

🎯 The Brief
OpenDriveLab releases AgiBot World, a massive robotics dataset featuring 1M+ trajectories from 100 robots across 100+ real-life scenarios in 5 domains, enabling advanced policy learning for complex robotic manipulation tasks.
⚙️ The Details
→ The dataset demonstrates significant capabilities in contact-rich manipulation, long-horizon planning, and multi-robot collaboration. The system integrates cutting-edge hardware including visual tactile sensors, 6-DoF dexterous hands, and mobile dual-arm robots.
→ Built on the LeRobot library v2.0, the project provides comprehensive tools for data conversion and policy training. A Jupyter notebook implementation allows straightforward training of diffusion policies on the dataset.
→ The development roadmap includes Beta release with expanded data collection targeting 1,000,000 trajectories, implementation of baseline models including ACT, DP3, and OpenVLA, followed by a comprehensive platform launch featuring teleoperation and training toolkits.
→ The project is released under CC BY-NC-SA 4.0 license, making it accessible for research purposes while maintaining attribution requirements.
🧠 Olmo 2 Released Their Tech Report, Reveals The Engineering Secrets And Training Detail For One Of The Few Remaining Frontier Fully Open Models
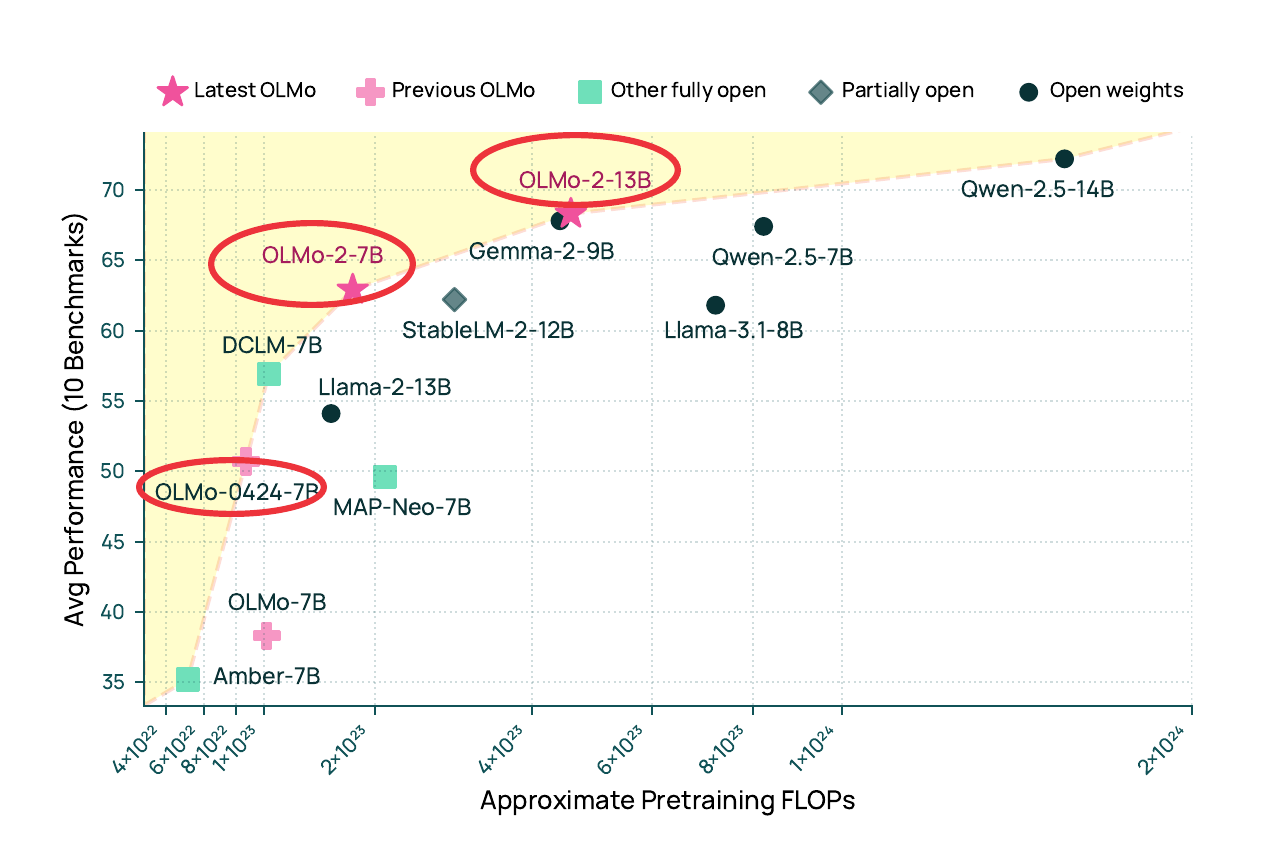
🎯 The Brief
Allen AI’s OLMo 2, is a fully open 7B and 13B parameter LLM family trained on up to 5T tokens, establishing new benchmarks in open model development through comprehensive training infrastructure, stability improvements, and novel data mixing strategies. The models achieve performance competitive with Qwen 2.5, Gemma 2, and Llama 3.1.
⚙️ The Details
→ The architecture features significant stability improvements through RMSNorm, QK-norm, and z-loss regularization. A custom initialization scheme preserves activation/gradient norms across model scales, while synchronized garbage collection and asynchronous bookkeeping optimize training throughput.
→ The training process introduces Dolmino Mix 1124, a specialized data curriculum used during model annealing. The innovative "microannealing" technique enables rapid evaluation of data source impacts with only 10B tokens, rather than full training runs.
→ Infrastructure spans two clusters: Jupiter (1,024 H100 GPUs) and Augusta (160-node Google Cloud). The setup achieves carbon emissions of 52 tCO2eq for 7B and 101 tCO2eq for 13B models.
→ 🐪 Post-training leverages the Tulu 3 recipe with multi-stage RLVR fine-tuning, demonstrating the portability of instruction-tuning approaches across architectures. The entire development pipeline, including code, data, and infrastructure details, is released openly.
🗞️ Byte-Size Brief
Elon Musk announced that Grok 3, an AI model developed by xAI, has completed its pre-training phase. The model's training involved 100,000 Nvidia H100 GPUs, which is 10X more compute than Grok 2.
LLMs are becoming more brain like as they advance, researchers discover. Neural responses in human brains match information processing patterns in advanced LLMs during language tasks. More surprisingly, as LLM performance increases, their alignment with the brain's hierarchy also increases. This means that the amount and type of information extracted over successive brain regions during language processing aligns better with the information extracted by successive layers of the highest-performing LLMs than it does with low-performing LLMs.
🧑🎓 Deep Dive Tutorial
📚 Why the deep learning boom caught almost everyone by surprise

This blog dives deep into how three contrarian tech visions - neural nets, GPUs, and big datasets - unexpectedly converged to spark the AI revolution.
📚 What you will learn
Know the fundamental components that created modern AI:
Backpropagation algorithm mechanics for training deep neural networks
Core architecture of convolutional neural networks (CNN) and their evolution from LeNet to AlexNet
CUDA platform's parallel computing capabilities for neural network acceleration
ImageNet's data collection and validation methodology using Amazon Mechanical Turk
Practical insights into:
Parallel GPU computing architecture for neural network training
Scaling challenges in large dataset creation and validation
CNN architecture optimization for improved accuracy
Integration patterns between neural nets, GPUs, and training data
Performance benchmarking techniques across different model architectures
Market implications and technological validation of contrarian approaches in AI development
Microsoft made a nice press release out of their spend. But, Amazon is already at/near this amount. With further increases expected in 2025 -"Amazon CEO Andy Jassy said the company plans to spend about $75 billion on capex in 2024 and that he suspects the company will spend more in 2025. "The increase bumps here are really driven by generative AI," Jassy said during a call with analysts"