


Implementing Custom GridSearchCV and RandomSearchCV without scikit-learn

My YouTube Video Explaining K-Fold Cross Validation with Diagram
My YouTube Video implementing GridSearchCV from Scratch without using Sckit-Learn
Full Code in Kaggle and Github
Scikit-Learn offers two vehicles for optimizing hyperparameter tuning: GridSearchCV and RandomizedSearchCV.
GridSearchCV performs an exhaustive search over specified parameter values for an estimator (or machine learning algorithm) and returns the best performing hyperparametric combination. So, all we need to do is specify the hyperparameters with which we want to experiment and their range of values, and GridSearchCV performs all possible combinations of hyperparameter values using cross-validation. As such, we naturally limit our choice of hyperparameters and their range of values. Theoretically, we can specify a set of parameter values for ALL hyperparameters of a model, but such a search consumes vast computer resources and time.
RandomizedSearchCV evaluates based on a predetermined subset of hyperparameters, randomly selects a chosen number of hyperparametric pairs from a given domain, and tests only those selected. RandomizedSearchCV tends to be less computationally expensive and time consuming because it doesn’t evaluate every possible hyperparametric combination. This method greatly simplifies analysis without significantly sacrificing optimization. RandomizedSearchCV is often an excellent choice for high-dimensional data as it returns a good hyperparametric combination very quickly.
Here Implementing both from scratch with pure python.
GridSearchCV from Scratch
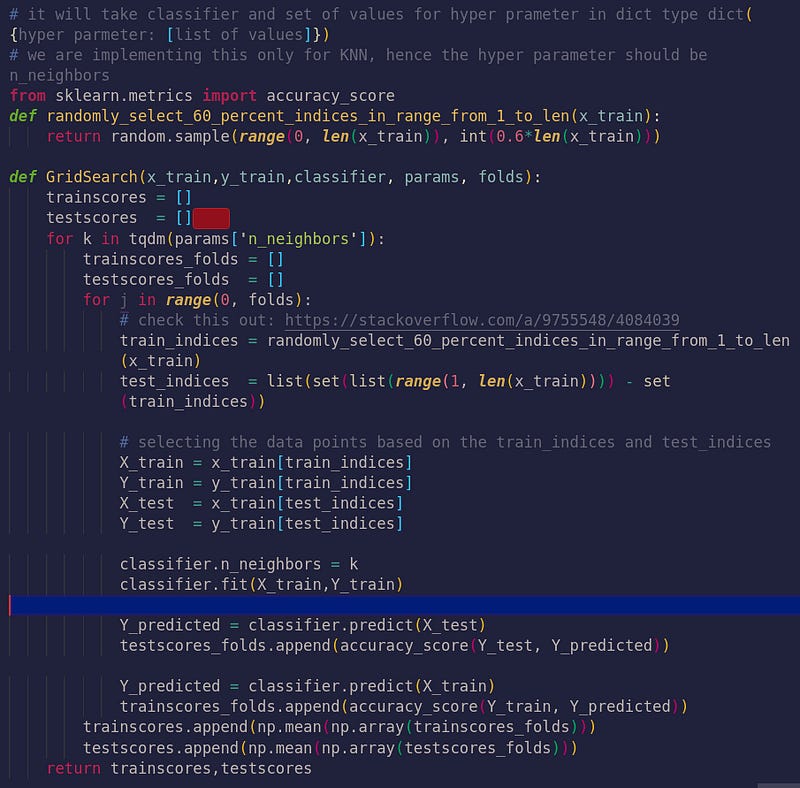
Now lets plot Hyper-parameter VS accuracy plot
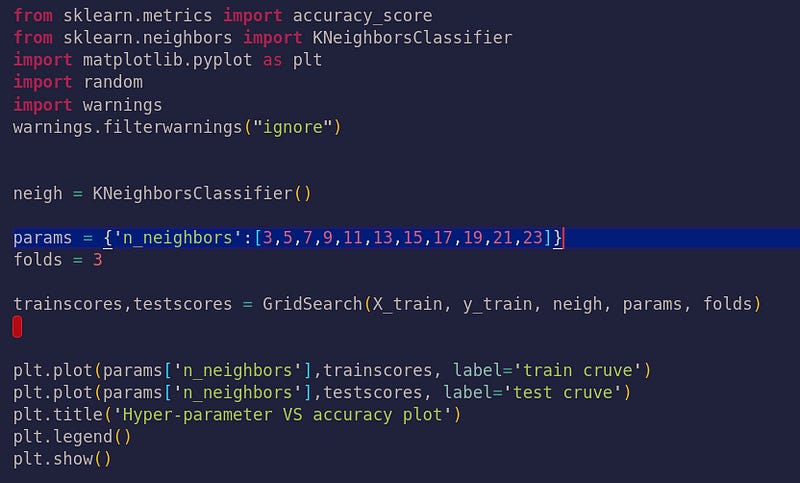
RandomSearchCV from scratch
Grid Search can be thought of as an exhaustive search for selecting a model. In Grid Search, the data scientist sets up a grid of hyperparameter values and for each combination, trains a model and scores on the testing data. In this approach, every combination of hyperparameter values is tried which can be very inefficient. For example, searching 20 different parameter values for each of 4 parameters will require 160,000 trials of cross-validation. This equates to 1,600,000 model fits and 1,600,000 predictions if 10-fold cross validation is used. While Scikit Learn offers the GridSearchCV function to simplify the process, it would be an extremely costly execution both in computing power and time.
An alternative way to perform hyperparameter optimization is to perform random sampling on the grid and perform k-fold cross-validation on some randomly selected cells.
Random Search sets up a grid of hyperparameter values and selects random combinations to train the model and score. This allows you to explicitly control the number of parameter combinations that are attempted. The number of search iterations is set based on time or resources. Scikit Learn offers the RandomizedSearchCV function for this process.
So reducing computational expense using RandomizedSearchCV() is its greatest benefit
For example
Searching 10 parameters (each range of 1000)
Require 10,000 trials of CV
100,000 model fits with 10-fold CV
100,000 predictions with 10-fold CV
RandomizedSearchCV() searches a subset of the parameters, and you control the computational "budget" You can decide how long you want it to run for depending on the computational time we have
Scikit-learn provides an optimizer called **RandomizedSearchCV()** to perform a random search for the purpose of hyperparameter optimization.
Notice that **RandomizedSearchCV()** requires the extra n_iter argument, which determines how many random cells must be selected. This determines how many times k-fold cross-validation will be performed. Therefore, by choosing a smaller number, fewer hyperparameter combinations will be considered and the method will take less time to complete. Also, please note that the param_grid argument is changed to param_distributions here. The param_distributions argument can take a dictionary with parameter names as keys, and either list of parameters or distributions as values for each key.
It could be argued that **RandomizedSearchCV()** is not as good as **GridSearchCV()** since it does not consider all the possible values and combinations of values for hyperparameters, which is reasonable. As a result, one smart way of performing hyperparameter tuning for deep learning models is to start with either **RandomizedSearchCV()** on many hyperparameters, or **GridSearchCV()** on fewer hyperparameters with larger gaps between them.
By beginning with a randomized search on many hyperparameters, we can determine which hyperparameters have the most influence on a model’s performance. It can also help narrow down the range for important hyperparameters. Then, you can complete your hyperparameter tuning by performing **GridSearchCV()** on the smaller number of hyperparameters and the smaller ranges for each of them. This is called the coarse-to-fine approach to hyperparameter tuning.
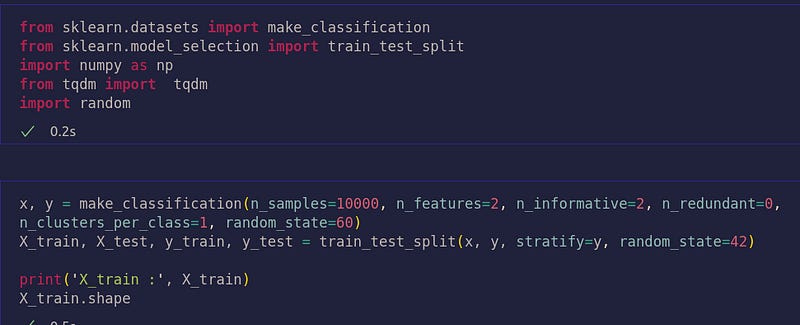
First create a dataset
pseudocode of our RandomSearchCV
The actual implementation of our custom RandomSearchCV
from sklearn.neighbors import KNeighborsClassifier from matplotlib.colors import ListedColormap import matplotlib.pyplot as plt import warnings warnings.filterwarnings("ignore")
Our Classifier is KNN, hence assign a variable to it._
neigh = KNeighborsClassifier() params_range = 50 number_of_total_folds = 3
Now invoking our custom function randomized_search_cv_custom(x_train,y_train,classifier, param_range, num_of_total_fold) and store the returned values_
testscores, trainscores, params = randomized_search_cv_custom(X_train, y_train, neigh, params_range, number_of_total_folds)
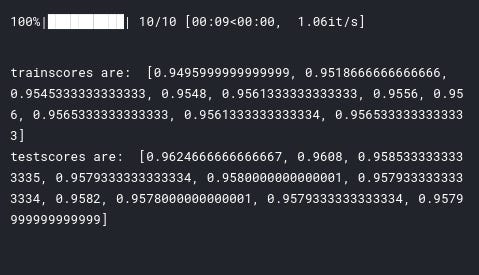
print('trainscores are: ', trainscores) print('testscores are: ', testscores)
Output
Plotting hyper-parameter vs accuracy plot
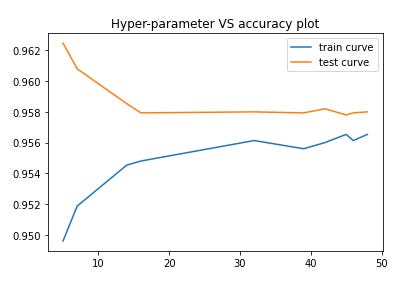
Now plotting hyper-parameter vs accuracy plot to choose the best hyperparameter_
plt.plot(params['n_neighbors'], trainscores, label='train curve') plt.plot(params['n_neighbors'], testscores, label='test curve') plt.title('Hyper-parameter VS accuracy plot') plt.legend() plt.show()
Full Code in Kaggle and Github
My YouTube Video Explaining K-Fold Cross Validation with Diagram
My YouTube Video implementing GridSearchCV from Scratch without using Sckit-Learn
My YouTube Video Explaining K-Fold Cross Validation with Diagram
My YouTube Video implementing GridSearchCV from Scratch without using Sckit-Learn