


How Gradient accumulation is implemented
Example code are in the context of a BERT based NLP project

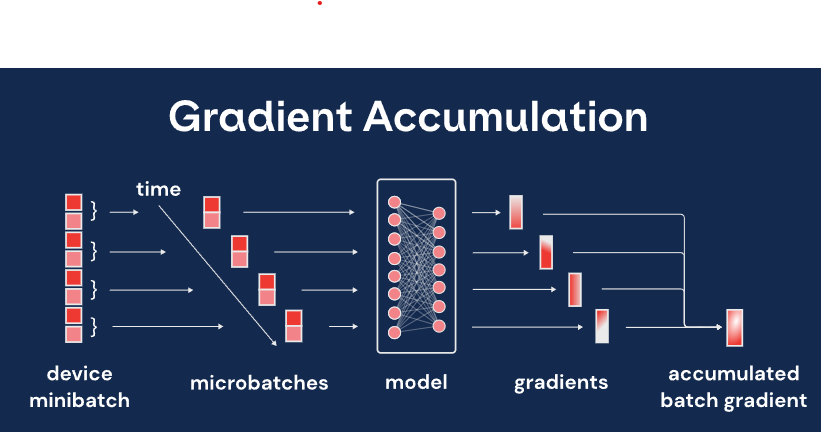
First the basics of Gradient Calculations in PyTOrch. The backward() method in PyTorch is used to compute the gradients of the tensors involved in a computational graph with respect to a given loss or objective function. It performs automatic differentiation
Here's how it works:
First, you need to set the requires_grad attribute of the tensors that you want to compute gradients for to True. This tells PyTorch to track the operations performed on those tensors and compute their gradients.
Next, you perform forward propagation by executing the operations on the tensors to compute the output. During this process, PyTorch builds a computational graph that keeps track of the operations and dependencies between tensors.
Once you have the output tensor, you define your loss function. The loss function typically compares the output with the desired target and calculates a scalar value that represents the "error" or "loss" of the model.
After defining the loss, you call the backward() method on the loss tensor. This triggers the backpropagation algorithm, which computes the gradients of all the tensors in the computational graph with respect to the loss.
The gradients are accumulated in the grad attribute of each tensor that had requires_grad set to True. These gradients represent the sensitivity of the loss with respect to each parameter in the model.
It's important to note that the backward() method accumulates gradients on subsequent calls. Therefore, if you need to compute gradients multiple times, you should set the gradients to zero before calling backward() using the zero_grad() method on the optimizer or manually zeroing out the grad attribute of each parameter tensor.
Now in below method, which is part of a BERT based NLP project Gradient accumulation is implemented.
| def train_one_epoch(model, optimizer, scheduler, dataloader, device, epoch): | |
| model.train() | |
| dataset_size = 0 | |
| running_loss = 0.0 | |
| bar = tqdm(enumerate(dataloader), total=len(dataloader)) | |
| """ The total argument in tqdm specifies the total number of iterations (or updates to the progress bar). In this case, len(dataloader) is used as the total which is the total number of batches in the dataloader. """ | |
| for step, data in bar: | |
| ids = data['input_ids'].to(device, dtype = torch.long) | |
| mask = data['attention_mask'].to(device, dtype = torch.long) | |
| targets = data['target'].to(device, dtype=torch.long) | |
| batch_size = ids.size(0) | |
| outputs = model(ids, mask) | |
| loss = criterion(outputs, targets) | |
| """ Gradient accumulation is happening in below loss calculation and .backward() | |
| Gradient accumulation involves accumulating gradients over multiple mini-batches before performing a weight update step. | |
| And that Gradient accumulation over several forward passes is achieved through the following two lines in the train_one_epoch() function: """ | |
| loss = loss / CONFIG['n_accumulate'] | |
| """ The `backward()` call on the next line calculates the gradients of the loss with respect to model parameters. Importantly, these gradients are not removed after the computation, they remain stored in the .grad attributes of the model parameters. | |
| BUT Instead of updating the parameters right away, add the computed gradients to the accumulated gradients. This step is repeated for a specified number of mini-batches. """ | |
| loss.backward() | |
| # After accumulating gradients over the desired number of mini-batches, perform the weight update step. | |
| if (step + 1) % CONFIG['n_accumulate'] == 0: | |
| # performs the actual parameter update using the accumulated gradients. | |
| optimizer.step() | |
| # clears out all the accumulated gradients from the parameters to prepare for the next round of accumulation. This happens after every CONFIG['n_accumulate'] batches, as checked by the if condition. | |
| optimizer.zero_grad() | |
| if scheduler is not None: | |
| scheduler.step() | |
| running_loss += (loss.item() * batch_size) | |
| dataset_size += batch_size | |
| epoch_loss = running_loss / dataset_size | |
| bar.set_postfix(Epoch=epoch, Train_Loss=epoch_loss, | |
| LR=optimizer.param_groups[0]['lr']) | |
| gc.collect() | |
| return epoch_loss |
Gradient accumulation - Explanation of line
if (step + 1) % CONFIG['n_accumulate'] == 0:
To understand gradient accumulation, let's first review the standard training procedure for deep learning models. In the standard approach, a mini-batch of training samples is fed into the model, and the gradients of the model parameters with respect to the loss function are computed using backpropagation. Then, these gradients are used to update the model's parameters using an optimization algorithm, such as stochastic gradient descent (SGD) or Adam.
In gradient accumulation, instead of updating the model's parameters after each mini-batch, we accumulate gradients over multiple mini-batches before performing the weight update step.
The main steps involved in gradient accumulation are as follows:
Initialize the gradients: Before starting the training loop, the gradients for all model parameters are initialized to zero.
Accumulate gradients: For each mini-batch, compute the gradients ( with loss.backward() ) of the model parameters with respect to the loss function using backpropagation.
BUT Instead of updating the parameters right away, add the computed gradients to the accumulated gradients. This step is repeated for a specified number of mini-batches.
Weight update step: After accumulating gradients over the desired number of mini-batches, perform the weight update step. With optimizer.step() This involves updating the model's parameters using the accumulated gradients. The update can be done using any optimization algorithm, such as SGD or Adam.
Reset gradients: After the weight update step, reset the accumulated gradients to zero to prepare for the next iteration. With optimizer.zero_grad()
In the above train_one_epoch() method in which line exactly we sum these gradients over several forward passes ?
Gradient accumulation over several forward passes is achieved through the following two lines in the train_one_epoch() function:
loss = loss / CONFIG['n_accumulate']
loss.backward()
In the first line, the loss for the current mini-batch is divided by CONFIG['n_accumulate']. This effectively scales down the gradient that will be computed in the next step. This is necessary because later we are summing (or rather, accumulating) CONFIG['n_accumulate'] of these gradients.