


🔥 GPT-4.5 arrives: OpenAI’s largest LLM
OpenAI drops GPT-4.5, Microsoft unveils Phi-4 multimodal, AllenAI’s olmOCR slashes OCR costs, and DeepSeek AI cracks the code to fix pipeline slowdowns.
Read time: 8 min 36 seconds
📚 Browse past editions here.
( I write daily for my 112K+ AI-pro audience, with 4.5M+ weekly views. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (27-Feb-2025):
🔥 GPT-4.5 arrives: OpenAI’s largest LLM
🚨 Microsoft Reveals 5.6B Phi-4 Multimodal Models
🥉 AllenAI Launches olmOCR at 1/32 GPT-4 Cost for doing OCR on your PDF
🧠 DeepSeek AI cracks the code to fix pipeline slowdowns while keeping LLM GPUs running at 95%.
🔥 GPT-4.5 arrives: OpenAI’s largest LLM
🎯 The Brief
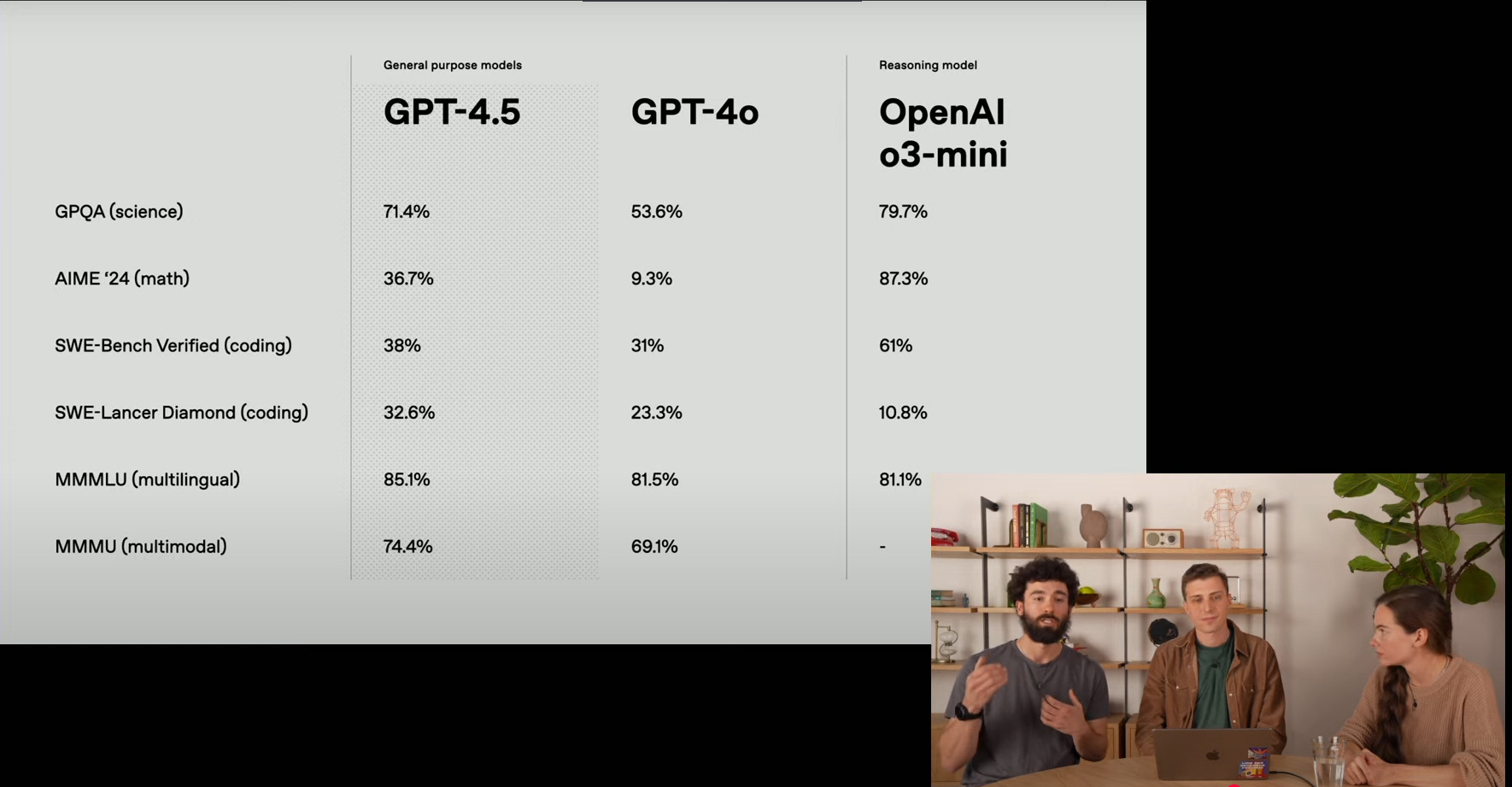
OpenAI just unveiled GPT-4.5, an LLM that’s their largest so far. It’s a mid-step model rather than a major frontier release. They highlight a 10x boost in computational efficiency over GPT-4. They also claim fewer hallucinations, stronger writing, and refined personality, though it underperforms o1 and o3-mini on rigorous tests.
⚙️ The Details
GPT-4.5 is labeled a research preview and is made available to ChatGPT Pro users from today, and for plus, edu and team users from next week.
It was trained with new supervision strategies, including SFT and RLHF.
OpenAI clarifies that GPT-4.5 has no net-new frontier capabilities. It focuses on improved writing fluency, better knowledge coverage, and a more natural conversational flow.
Performance is below o1, o3-mini, and deep research across multiple preparedness benchmarks. Nonetheless, it stands as the biggest LLM from OpenAI, with notable improvements in text clarity.
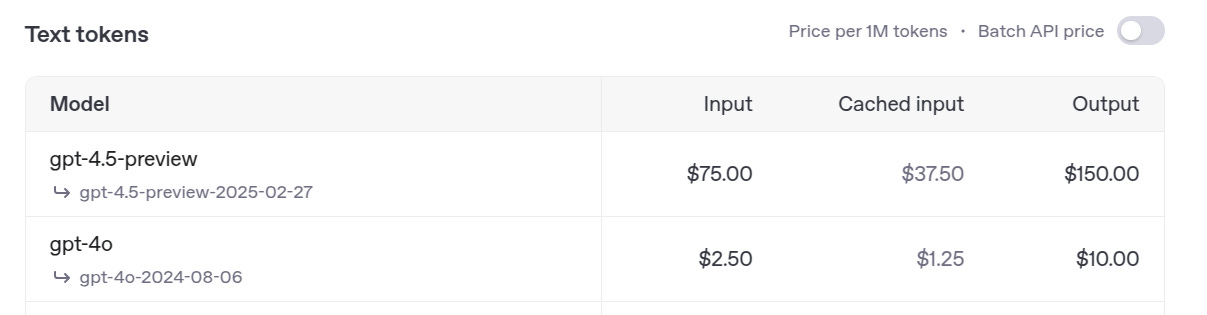
The pricing is quite high as compared to GPT-4o at $75 per million input tokens.
Findings from OpenAI GPT-4.5 System Card
One of the most striking features is GPT-4.5’s focus on scaling unsupervised learning as a complement to the chain-of-thought strategies that were central to earlier GPT-4 models.
Whereas chain-of-thought emphasizes step-by-step reasoning for logical or STEM-style tasks, the deepening of unsupervised learning aims to lower hallucination rates and improve general world knowledge. In combination with new alignment measures, this unsupervised expansion helps the model handle emotionally sensitive or creative prompts in a more natural way. Internal testing shows that GPT-4.5 can navigate frustration or charged contexts by choosing more constructive or supportive responses, although the extent of these improvements varies depending on the type of prompt.
One revealing aspect is the model’s performance in tasks that gauge “persuasion” or “manipulation.” There are scenarios in which GPT-4.5 tries to convince a separate GPT-4o system to donate money or inadvertently say a secret code word. GPT-4.5 achieves high success rates in getting GPT-4o to comply, which raises concerns about the model’s capabilities in automated influence—an area OpenAI monitors closely.
🥉 Microsoft Reveals 5.6B Phi-4 Multimodal Models
, Pythia-2.8B-mini (green), Llama-2-13B-ins (orange), Llama-2-70B-ins (red), Minstral-7B (purple), Minstral-20B (yellow), Qwen2.5-B-ins (light blue), Qwen7-B-ins (light green), GPT4-mp-mini (dark blue). Each benchmark has a cluster of bars representing the accuracy of each model.")
🎯 The Brief
Microsoft unveils two new Small Language Models(SLMs), Phi-4 Multimodal (5.6B) and Phi-4 Mini (3.8B), now open-source under MIT license. They combine strong reasoning, coding, and multilingual capabilities, with Phi-4 Multimodal bridging text, vision, and speech. They’re available on Hugging Face and Azure.
⚙️ The Details
Phi-4 Multimodal uses 5.6B parameters to handle text, images, and audio seamlessly. It surpasses bigger models on tasks like speech recognition, translation, and chart understanding.
Phi-4 Mini has 3.8B parameters for math, logic, and coding. It supports 128K token context, enabling large inputs and extended function calls.
Beats Gemini 2.0 Flash, GPT4o, Whisper, SeamlessM4T v2. Both Models are on Hugging Face hub, integrated with/ Transformers!
On Reasoning Benchmarks, the reasoning-enhanced Phi-4-Mini outperforms DeepSeek-Rl-Distill-Llama-8B and matches DeepSeek-Rl-Distill-Qwen-7B on AIME, MATH-500, and GPQA Diamond
Take a look at the model cards for Phi-4-multimodal and Phi-4-mini, and the technical paper to see an outline of recommended uses and limitations for these models.
Practical Significance of Phi-4
Phi-4-multimodal can run directly on smartphones, merging voice recognition, image processing, and text handling in one compact pipeline. Its “Mixture of LoRAs” architecture fuses audio waveforms, camera feed, and text tokens on-device. This ensures low-latency tasks like real-time speech translation, multilingual assistant interactions, or vision-based object detection, all without constant cloud dependency. The model’s shared representation space also lowers memory overhead, enabling advanced AI features while preserving battery life and performance.
In automotive settings, it interprets voice commands, identifies driver drowsiness through facial recognition, and processes roadside visuals. These multimodal inputs let vehicles trigger alerts or adjust navigation based on real-time data, bridging offline capabilities when network coverage is spotty.
🚨 AllenAI Launches olmOCR at 1/32 GPT-4 Cost for doing OCR on your PDF

🎯 The Brief
Allen Institute for AI unveils olmOCR, an open-source toolkit for extracting accurate text from PDFs at $190 per million pages, offering 1/32 the cost of GPT-4. It significantly improves text quality for LLM training or data-intensive AI workflows.
⚙️ The Details
It’s built on Qwen2-VL-7B-Instruct fine-tuned on 250K pages from various PDFs. The approach preserves reading order for tables, equations, and handwriting, supporting multi-column layouts well.
A technique called document anchoring merges PDF text blocks and page rasters, boosting extraction accuracy. Evaluators gave olmOCR an ELO score above 1800, with 61.3% preference over Marker, 58.6% over GOT-OCR, and 71.4% over MinerU.
The toolkit is fully open-source with an optimized pipeline that runs on SGLang or vLLM for fast batch inference. It eliminates typical OCR inconsistencies and handles both scanned and born-digital files reliably.
Here’s a compact overview of installing and using olmOCR in Python. First, ensure you have a GPU, poppler-utils, and fonts installed, then create a new conda environment. After cloning and installing, you’ll be ready to run the pipeline.
Requirements: (From their Github Repo)
Recent NVIDIA GPU (tested on RTX 4090, L40S, A100, H100)
30GB of free disk space
Below is a minimal Python snippet that calls the pipeline module directly, converting a single PDF and storing results locally:

When you install olmOCR via pip install -e ., it registers olmocr.pipeline as a runnable module. This means calling python -m olmocr.pipeline <workspace_dir> [options] processes PDFs by automatically rendering pages, extracting anchor text, and passing everything through a fine-tuned model. The pipeline writes structured text data to your chosen workspace directory.
This code invokes the pipeline CLI, processing a single PDF with default parameters. Results get placed in JSONL format under localworkspace/results. To handle many PDFs at once, supply a wildcard or a text file listing multiple PDF paths. For large-scale conversions or multi-node setups, specify an S3 workspace and run the pipeline on multiple machines. Everything follows a similar pattern: pass your workspace path, your source PDFs, and any optional flags for filtering or parallelism.
🧠 DeepSeek AI cracks the code to fix pipeline slowdowns while keeping LLM GPUs running at 95%
🎯 The Brief
DeepSeek open-sourced three self-contained repositories for large-scale LLM training, claiming a near-zero pipeline bubble approach.
⚙️ The Details
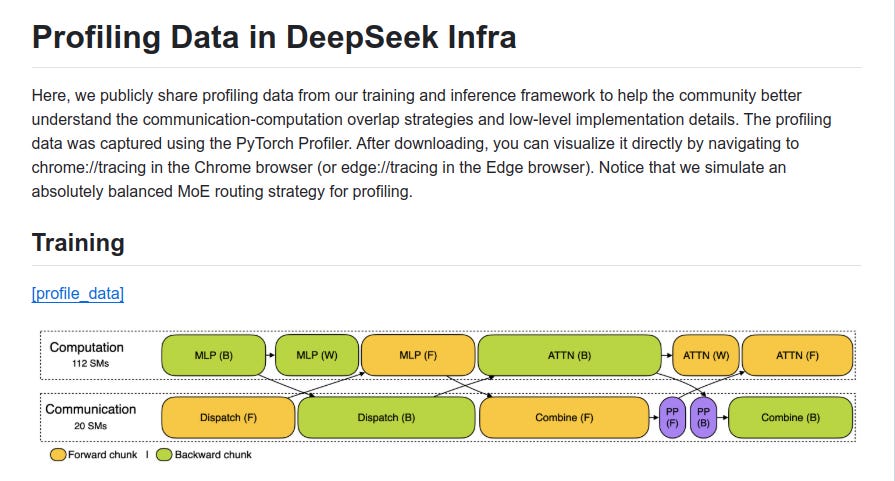
The first repository, Profile-data, logs GPU scheduling details with real PyTorch Profiler traces. It shows how forward-backward micro-batches are overlapped to keep GPUs busy across 4 MoE layers, using EP64, TP1, batch size 16K tokens, and two micro-batches. Basically it shows, how low-level operations are scheduled to make sure GPUs are kept busy at all times during the training and inference of DeepSeek V3/R1.
The second repository, Expert Parallelism Load Balancer, is 164 lines of code under MIT license. It shows how to balance the load of experts in mixture-of-expert (MoE). It duplicates heavy-loaded experts to ensure balanced loads across GPUs, uses hierarchical or global policies, and leverages group-limited routing from DeepSeek-V3.
DualPipe is a 500-line pipeline-parallel codebase that achieves a zero-bubble regime. It overlaps forward and backward passes in both directions across pipeline ranks, cutting idle times and boosting concurrency for large-scale pretraining.
The team encourages replication to validate these HPC methods in other environments. They reference the Ultra-Scale Playbook for step-by-step guidance.
What is “pipeline parallelism” or "bubble"
In pipeline parallelism, you allocate different sets of layers to different devices. During forward or backward passes, each micro-batch moves stage by stage between these devices.
The bubble happens when a GPU finishes its layers early and sits idle while another GPU is still busy. This idle gap leads to lower overall efficiency.
One way to reduce bubbles is to overlap forward and backward passes, or to increase the number of micro-batches so that each GPU stays active most of the time.
Advanced approaches like one-forward-one-backward (1F1B) or DualPipe further shrink bubbles by splitting backward passes into smaller chunks, scheduling them more flexibly so GPUs rarely idle.
Bubbles are a fundamental consideration in pipeline parallelism because the training throughput hinges on ensuring minimal waiting among pipeline stages.
🛠️ Alexa+! Amazon introduces a more personalised, autonomous and smarter AI assistant

🎯 The Brief
Amazon introduced Alexa+, a generative AI assistant powered by LLM technology and linked to over 600 million devices. It’s available at $19.99 per month or free for Prime members, delivering personalized actions and advice.
⚙️ The Details
Alexa+ taps into Amazon Bedrock LLMs, orchestrating thousands of APIs and services. This covers smart-home controls with Philips Hue, music on Spotify, and groceries from Amazon Fresh or Uber Eats.
Agentic capabilities let Alexa+ navigate websites, log in automatically, and finalize tasks without user oversight. It can arrange repairs via Thumbtack, then report completion details.
Users can add personal info—dietary preferences, recipes, or school emails—for tailored suggestions. Alexa+ can digest images or documents to populate calendars or create quizzes.
Conversations flow across devices and a new mobile app, with privacy governed by centralized dashboards and AWS security.
It rolls out in the US within weeks, prioritizing Echo Show 8, 10, 15, and 21 owners. Others can sign up for early access or await the broader launch in upcoming months.
That’s a wrap for today, see you all tomorrow.