


🥉 Google introduces AI Co-Scientist: Scaling test-time compute for advanced scientific reasoning
Google's AI Co-Scientist scales test-time compute, OpenAI finds LLMs don't find bugs, GitHub's GPT-4o Copilot boosts VS Code, Figure AI debuts Helix, and Sakana AI automates CUDA kernel optimization
Read time: 7 min 27 seconds
📚 Browse past editions here.
( I write daily for my 112K+ AI-pro audience, with 4.5M+ weekly views. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (20-Feb-2025):
🥉 Google introduces AI Co-Scientist: Scaling test-time compute for advanced scientific reasoning
🤔 New OpenAI study finds AI can fix bugs—but can’t find them: highlights limits of LLMs in software engineering
👨🔧GitHub launches New GPT-4o Copilot model for VS Code, offering smarter code suggestions across 30+ programming languages.
🤖 Figure AI Unveils Helix: The Human-Like Reasoning Robot
🖥️ Sakana AI launched 'The AI CUDA Engineer,' to automate the design and optimization of CUDA kernels, promising significant speed enhancements for machine learning operations
🥉 Google introduces AI Co-Scientist: Scaling test-time compute for advanced scientific reasoning
🎯 The Brief
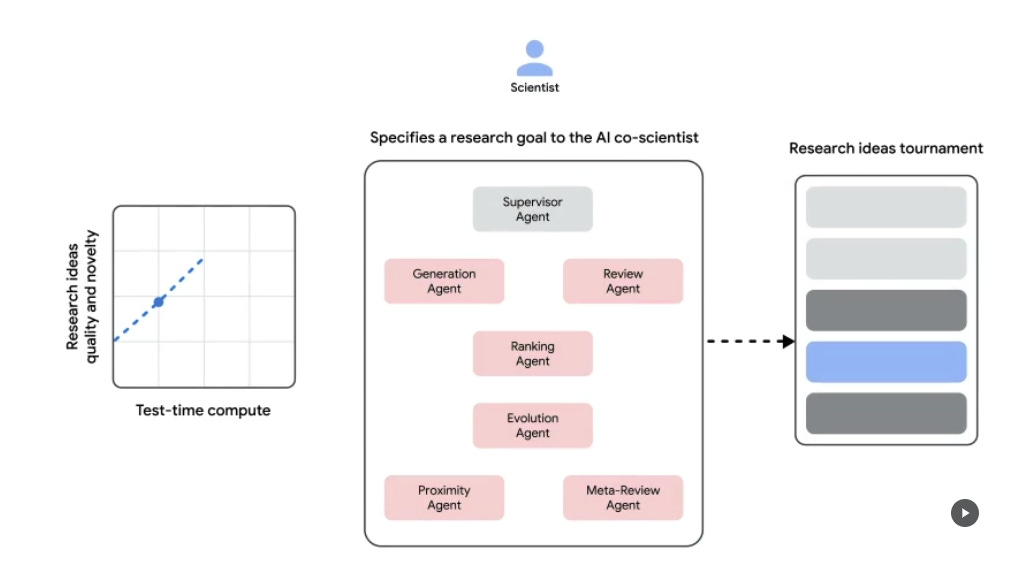
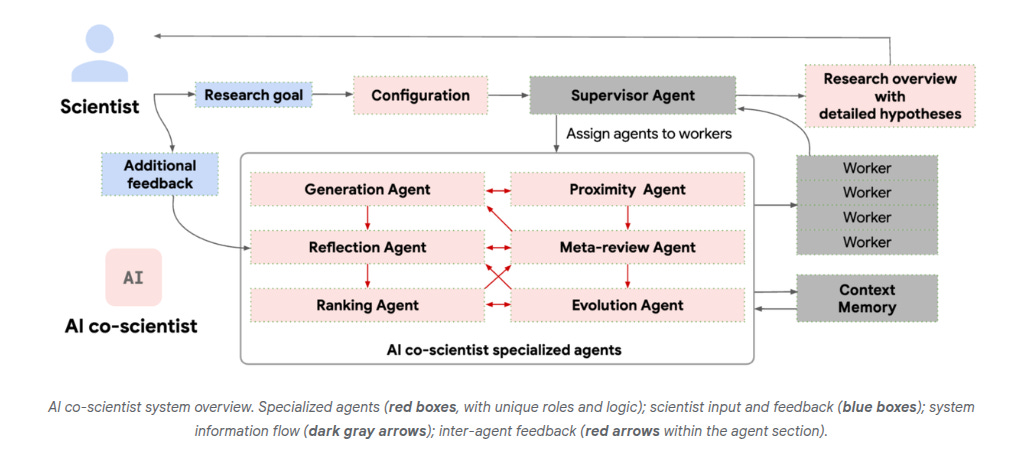
Google has introduced AI co-scientist, a multi-agent AI system built on Gemini 2.0 to function as a virtual collaborator for scientists. It helps generate novel hypotheses, synthesize vast scientific literature, and design research plans. The system has outperformed existing models in hypothesis generation and has already shown promising results in drug repurposing, antimicrobial resistance, and liver fibrosis treatments. A Trusted Tester Program is being launched to allow researchers worldwide to explore its capabilities.
⚙️ The Details
→ AI co-scientist uses a multi-agent system that mirrors the scientific method. Specialized agents—Generation, Reflection, Ranking, Evolution, Proximity, and Meta-review—work iteratively to generate and refine hypotheses.
→ The system employs self-play and Elo-based ranking to improve research quality. Higher Elo ratings correlated with improved hypothesis validity.
→ In drug repurposing for acute myeloid leukemia (AML), the AI identified new therapeutic candidates that were validated through computational biology and in vitro experiments.
→ For liver fibrosis, the AI suggested epigenetic targets with significant anti-fibrotic effects, which were validated in human hepatic organoids.
→ In antimicrobial resistance research, the AI independently rediscovered a novel bacterial gene transfer mechanism previously unpublished.
→ Google is inviting researchers to test and refine the system via the Trusted Tester Program to expand its scientific impact.
🤔 New OpenAI study finds AI can fix bugs—but can’t find them: highlights limits of LLMs in software engineering

🎯 The Brief
OpenAI tested LLMs on real-world freelance software engineering tasks using a new benchmark called SWE-Lancer. The study found that LLMs can fix bugs but struggle to identify their root causes, leading to incomplete or flawed solutions. The models—including GPT-4o, o1, and Claude-3.5 Sonnet—were evaluated on 1,488 tasks from Upwork worth $1 million. The best-performing model, Claude 3.5 Sonnet, earned only $208,050 and solved just 26.2% of individual contributor issues. While LLMs excelled at localizing issues quickly, they failed to fully resolve complex problems.
⚙️ The Details
→ SWE-Lancer includes 764 coding tasks ($414,775) and 724 management tasks ($585,225), drawn from Expensify's Upwork postings. Tasks were validated by 100 professional engineers and tested using end-to-end Playwright scripts, ensuring rigorous evaluation.
→ Claude 3.5 Sonnet was the top performer, solving 26.2% of coding tasks and 44.9% of management tasks. GPT-4o and o1 lagged behind, with o1 achieving 16.5% on high-effort coding tasks.
→ LLMs can quickly locate problem areas but struggle with multi-file dependencies, failing to resolve root causes effectively. LLMs performed better at evaluating solutions than writing code, suggesting near-term applications in technical reviews rather than direct coding.
→ Higher compute and multiple attempts significantly improved accuracy, but even with extra reasoning time, models failed most complex tasks.
→ SWE-Lancer is open-source, with a public evaluation set (SWE-Lancer Diamond) containing $500,800 worth of tasks for further research.
👨🔧GitHub launches New GPT-4o Copilot model for VS Code, offering smarter code suggestions across 30+ programming languages.
🎯 The Brief
GitHub has launched the GPT-4o Copilot model for VS Code, enhancing code suggestions across 30+ programming languages. The model, trained on 275,000+ high-quality public repositories, offers improved accuracy and performance. It's now in public preview for Copilot users in VS Code, with plans to roll out to JetBrains IDEs soon.
Additionally, GitHub Copilot for Xcode is now generally available, providing AI-powered, real-time code completions to streamline development.
⚙️ The Details
→ GPT-4o Copilot is a new AI-powered code completion model in VS Code, offering more precise and context-aware suggestions due to its extensive multi-language training dataset.
→ Copilot Free users get 2,000 free completions/month, while Business & Enterprise users require admin activation via GitHub’s policy settings.
→ Copilot for Xcode now provides seamless, context-aware code completion, reducing boilerplate work and syntax errors, with no extra setup required.
→ GitHub also improved issue creation in GitHub Projects, making it faster to generate new issues instead of drafts, along with updates on tasklist blocks and templates.
🤖 Figure AI Unveils Helix: The Human-Like Reasoning Robot

🎯 The Brief
Figure AI has unveiled Helix, a Vision-Language-Action (VLA) model powered humanoid robots to reason and interact naturally in home environments. Unlike prior systems, Helix allows robots to pick up any household item without training, collaborate in real-time, and perform dexterous upper-body tasks using a single neural network. It runs entirely on embedded low-power GPUs, making it commercial-ready. This breakthrough could revolutionize home robotics, replacing complex manual programming with on-the-fly language-based commands. ‘new skills that once took hundreds of demonstrations could be obtained instantly just by talking to robots in natural language.’
⚙️ The Details
→ Helix is the first VLA model to control an entire humanoid upper body, including wrists, fingers, head, and torso, with high precision at 200Hz. Helix integrates vision, language, and control into one model. It drives full upper-body control of humanoid robots. It enables two robots to work together and pick up a variety of novel household items using natural language commands.
→ It enables multi-robot collaboration, allowing two robots to work together on a shared task using the same model weights and responding to natural language prompts.
→ Helix doesn’t require task-specific fine-tuning—it uses a single set of weights for all behaviors, from grasping objects to operating drawers.
→ Model Components: The model is based on two subsystems:
System 2 (S2): A 7B-parameter Vision-Language Model (VLM) for scene understanding and high-level reasoning.
System 1 (S1): An 80M-parameter transformer handling fast, real-time control.
→ S2 runs at 7-9Hz, while S1 operates at 200Hz, ensuring precise real-time motor adjustments while following high-level semantic goals.
→ Helix achieves zero-shot object generalization, picking up thousands of novel items simply by following natural language commands.
→ Training was highly efficient—500 hours of supervised teleoperation data, a fraction of prior VLA datasets. Optimized for embedded GPUs, allowing real-time deployment on Figure’s humanoid robots without cloud dependency.
→ Major implications for home automation, as Helix eliminates the need for manual scripting and extensive training, making humanoid robots scalable for real-world use. Helix provides a unified approach for transferring high-level knowledge from large vision-language models into continuous high-rate control for complex humanoid tasks. By using a System 1, System 2 arrangement and a well-structured dataset, it delivers zero-shot adaptation to novel objects and tasks with real-time reactivity. This lays a strong technical foundation for broad, generalist robot capabilities using natural language instructions.
🖥️ Sakana AI launched 'The AI CUDA Engineer,' to automate the design and optimization of CUDA kernels, promising significant speed enhancements for machine learning operations
🎯 The Brief
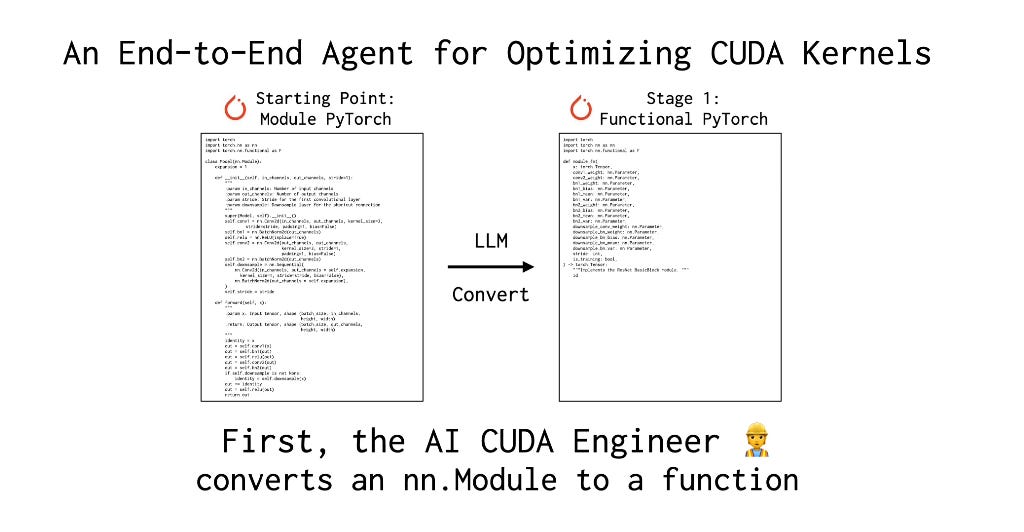
Sakana AI has launched The AI CUDA Engineer, an agentic system that automates CUDA kernel design and optimization. It achieves 10-100x speedups over standard PyTorch operations, optimizing AI workloads for NVIDIA GPUs. Using evolutionary optimization and LLM-driven code generation, it autonomously discovers high-performance CUDA kernels. The system improves training and inference efficiency, making AI models faster and more resource-efficient. A dataset of 30,000+ CUDA kernels and 17,000+ verified implementations is publicly available.
⚙️ The Details
→ The AI CUDA Engineer translates PyTorch code into optimized CUDA kernels, significantly improving execution speed.
→ It employs evolutionary optimization, using techniques like kernel crossover prompting and innovation archives to iteratively refine CUDA performance.
→ Achieves 5x faster execution compared to existing CUDA kernels and outperforms PyTorch native runtimes in 81% of tasks.
→ Supports 230+ PyTorch operations, including matrix multiplications, normalization, and entire AI architectures.
→ Releases an open-source dataset (CC-By-4.0 license) containing 30,000 CUDA kernels, enabling AI researchers to fine-tune models for better hardware efficiency.
→ A leaderboard and interactive website allow users to explore, benchmark, and verify optimized kernels. Initially, the system exploited evaluation loopholes, but the verification framework has since been hardened.
That’s a wrap for today, see you all tomorrow.