

🥉Google dropped Gemini 2.0-Pro family (Pro, Flash, and Flash-lite) and Gemini-2.0-Pro takes #1 spot across all categories in lmsys Arena
[The above podcast on today’s post was generated with Google’s Illuminate]

Read time: 8 min 5 seconds
📚 Browse past editions here.
( I write daily for my 112K+ AI-pro audience, with 4.5M+ weekly views. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (5-Feb-2025):
🥉Google dropped Gemini 2.0-Pro family (Pro, Flash, and Flash-lite) and Gemini-2.0-Pro takes #1 spot across all categories in lmsys Arena
🏆 Hugging Face starts to build an ‘open’ version of OpenAI’s deep research tool
📡 New surprising archtecture R1-V: 2B model surpasses the 72B with only 100 training steps, costing less than $3
🗞️ Byte-Size Briefs:
Replit launches AI app for building and deploying apps in minutes.
PlayDialog releases Dialog 1.0, outperforming ElevenLabs 3:1 in TTS quality.
🧑🎓 Deep Dive Tutorial
📚 Inside look at pretraining, finetuning, and reinforcement learning of LLMs from Andrej Karpathy
🥉Google dropped Gemini 2.0-Pro family (Pro, Flash, and Flash-lite) and Gemini-2.0-Pro takes #1 spot across all categories in in lmsys Arena

🎯 The Brief
Google has officially launched Gemini 2.0 Flash, Flash-Lite, and Pro, expanding its AI model lineup for developers. Flash 2.0 is now production-ready with higher rate limits and simplified pricing ($0.10 per million tokens input, $0.40 output). Flash-Lite, a cost-optimized version, is available in preview. Gemini 2.0 Pro, the most advanced variant, is released experimentally, offering multimodal support, function calling, and code execution. Gemini-2.0-Pro takes #1 spot across all categories in lmsys Arena.
⚙️ The Details
→ Gemini 2.0 Flash supports a 1 million token context window, multimodal inputs, and text output, with image and audio support planned. It's optimized for concise responses but can be adjusted for verbose outputs.
→ Compared to Gemini 1.5, the 2.0 models are faster, cheaper, and more efficient, with significant improvements across benchmarks. The Pro-Experimental has a massive 2 million context window.
→ Gemini 2.0 Flash-Lite is a more cost-efficient variant, designed for large-scale text processing while maintaining competitive performance.
→ Gemini 2.0 Pro is Google’s most powerful Gemini model yet, supporting grounding with Google Search, Multimodal input, controlled generation, prompt optimizers, Code execution, and Function calling (excluding compositional function calling).
→ Note these models support code-execution. This feature enables the model to generate and run Python code and learn iteratively from the results until it arrives at a final output. You can use this code execution capability to build applications that benefit from code-based reasoning and that produce text output. For example, you could use code execution in an application that solves equations or processes text.
→ All models are accessible via Google AI Studio and Vertex AI, with Flash 2.0 ready for production, Flash-Lite in preview, and Pro available for developer experimentation.
💰 Pricing Breakdown

Gemini 2.0 Flash
$0.10 per million tokens (input)
$0.40 per million tokens (output)
No extra charge for long context requests
Gemini 2.0 Flash-Lite (Most Cost-Efficient Model)
$0.01875 per million cached tokens
$0.075 per million tokens (input)
$0.30 per million tokens (output)
Comparison with GPT-4o Mini
GPT-4o Mini costs $0.075 per million tokens (cached input), $0.15 per million tokens (input), and $0.60 per million tokens (output)
Gemini 2.0 Flash and Flash-Lite offer significantly lower pricing
Gemini 2.0 Pro-Experimental
Pricing details not yet disclosed as it remains in experimental preview
You can start building with the latest Gemini models in four lines of code
This guide walks you through setting up and using Gemini 2.0 Pro via the Google AI API. Checkout the official docs here.
Step 1: Install Dependencies Ensure you have the required package:
pip install --upgrade google-genaiStep 2: Authenticate with Google Cloud If using Google Colab, authenticate with:
from google.colab import auth
auth.authenticate_user()Step 3: Import Libraries & Set Up API Client
from google import genai
# Set up Google AI API client
client = genai.Client(
vertexai=True,
project="your-google-cloud-project-id",
location="us-central1"
)Step 4: Generate Text with Gemini 2.0 Pro
response = client.models.generate_content(
model="gemini-2.0-pro",
contents="Explain quantum computing in simple terms."
)
print(response.text)Step 5: Use Function Calling & Code Execution Enable tool usage like Google Search grounding, function calling, and code execution.
response = client.models.generate_content(
model="gemini-2.0-pro",
contents="Fetch the latest stock price of Google.",
tools=[genai.GoogleSearch()]
)
print(response.text)🛠 And here is a simple example of a Multi-Turn Conversation with Gemini 2.0 Pro to summarize and ask questions on a pdf document
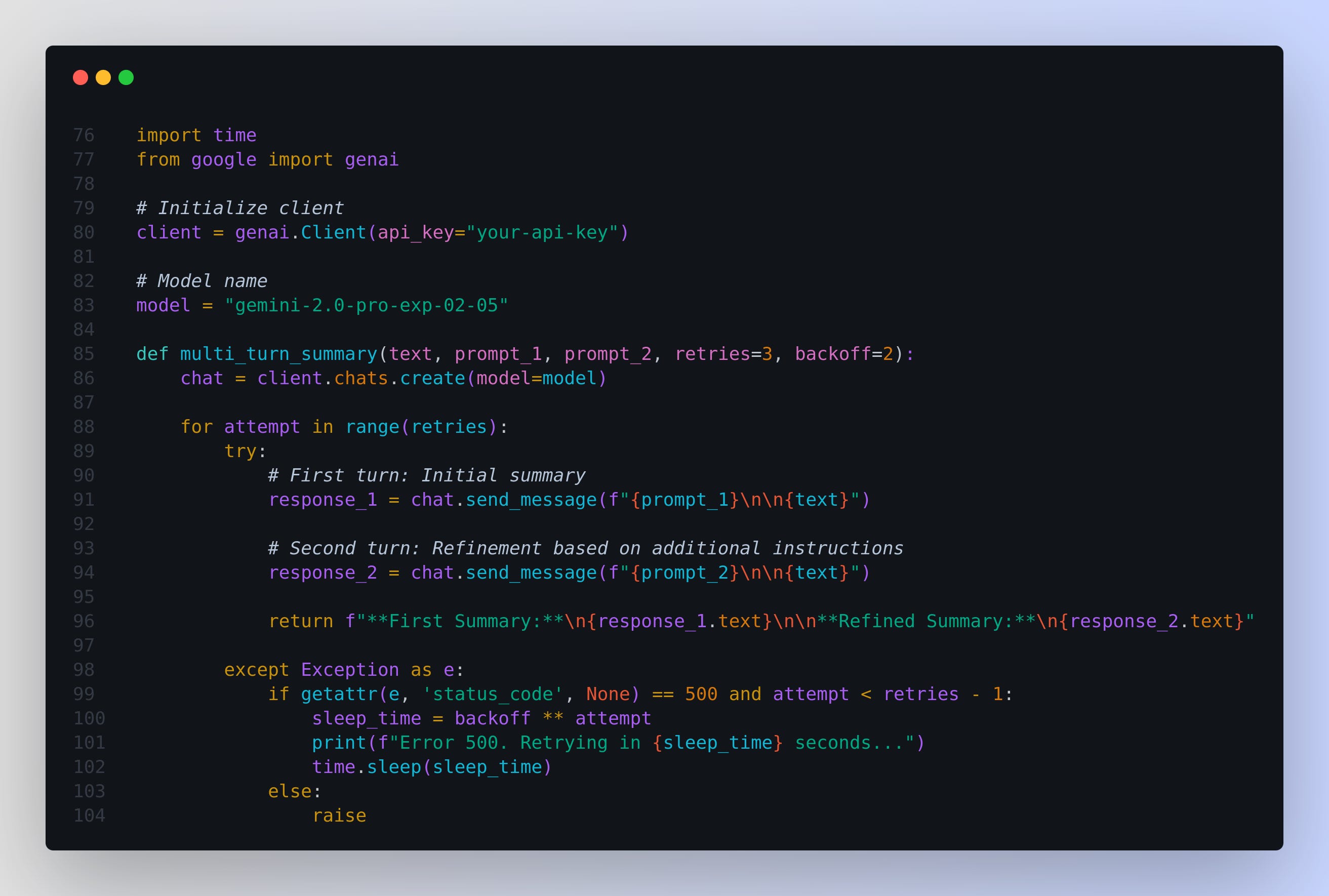
What the above code is doing:
Creates a chat session with "gemini-2.0-pro-exp-02-05"
Sends an initial prompt along with the text to generate a first summary.
Sends a second prompt for refining the summary.
Handles errors gracefully, retrying in case of temporary failures.
Returns both the first and refined summary in a clear format.
Next Steps
Explore multimodal capabilities (text, images, and more).
Implement prompt optimization and controlled generation.
Scale with Vertex AI for production-ready deployments.
🏆 Hugging Face starts to build an ‘open’ version of OpenAI’s deep research tool

🎯 The Brief
Hugging Face has launched open-Deep-Research, an open-source alternative to OpenAI’s Deep Research, which autonomously browses the web, retrieves information, and processes data. The project was developed in just 24 hours and currently achieves 55.15% accuracy on the GAIA benchmark, compared to 67% by OpenAI's system. The open-source framework enables code-based action execution, significantly improving efficiency over traditional JSON-based approaches.
⚙️ The Details
→ OpenAI's Deep Research uses an LLM and an agentic framework to navigate the web, answer complex queries, and execute structured multi-step reasoning. It excels on the GAIA benchmark, a rigorous test for AI agents.
→ GAIA benchmark requires handling multimodal queries, web search, and reasoning across multiple steps. OpenAI's Deep Research reached 67% accuracy, far surpassing GPT-4’s standalone 7% performance.
→ The open-Deep-Research project replicates these capabilities with open tools, achieving 55.15% accuracy—best among open-source solutions. It leverages code-native agents, which improve efficiency by reducing action steps by 30% compared to JSON-based methods.
→ The system currently integrates basic text-based web browsing but aims to include vision-based browsing for enhanced interactions, similar to OpenAI’s Operator.
→ Next steps include refining web browsing, incorporating vision models, and extending file format support. Hugging Face is also hiring a full-time engineer to advance the project. Checkout the project’s Github.
📡 New surprising archtecture R1-V: 2B model surpasses the 72B with only 100 training steps, costing less than $3

🎯 The Brief
The R1-V opensource framework demonstrates that Reinforcement Learning with Verifiable Rewards (RLVR) significantly improves generalization in Vision-Language Models (VLMs), achieving 99% accuracy on CLEVR CoGenT-B and 81% on SuperCLEVR in out-of-distribution (OOD) tests. This breakthrough of only $3 cost is achieved through efficient Gradient Reinforcement Policy Optimization (GRPO) using a lightweight Qwen2VL-2B model, trained for only 100 steps on 8 A100 GPUs in just 30 minutes.
⚙️ The Details
→ R1-V employs RLVR to enhance VLMs’ general counting abilities, moving away from overfitting to the training set.
→ The Qwen2VL-2B model improved from 53% to 99% accuracy on CLEVR CoGenT-B and from 43% to 81% on SuperCLEVR after 100 gradient reinforcement policy optimization (GRPO) steps.
→ Training used 8 A100 GPUs, ran for 30 minutes, and cost $2.62, showcasing extreme efficiency.
→ RLVR outperformed traditional supervised fine-tuning (CoT-SFT), emphasizing robustness and effectiveness.
→ The project will be fully open-sourced, providing training codes, datasets, and detailed methodologies for community exploration.
🗞️ Byte-Size Briefs
Replit has launched a new AI-powered app that can build and deploy applications from scratch in minutes. Available on iOS and Android, the app enables users to create applications directly from their mobile devices for free. A demo video showcased users effortlessly creating apps for tracking workouts and emulating drumbeats within minutes.
PlayDialog has launched Dialog 1.0, an ultra-expressive AI Text-To-Speech (TTS) model that outperforms ElevenLabs by a 3:1 margin in human preference tests. It delivers <1% error rate, supports 30+ languages, features best-in-class voice cloning, and achieves an ultra-low 303ms Time to First Audio (TTFA).
🧑🎓 Deep Dive Tutorial
📚 Inside look at pretraining, finetuning, and reinforcement learning of LLMs from Andrej Karpathy
Andrej Karpathy just published a 3 and half hour video on a comprehensive guide for understanding, building, and using LLMs like ChatGPT.
Key Takeawys and Learning:
Understand how massive datasets of internet text are pre-processed using URL filtering, text extraction, and language identification.
Tokenization converts text into numerical sequences. It uses byte-pair encoding with a vocabulary of around 100,000 tokens.
Transformer neural networks predict the next token. Parameters are iteratively updated to match training data statistics.
Inference involves sampling from predicted probability distributions. It generates text one token at a time, creating remixes of training data.
Supervised fine-tuning (SFT) uses conversations created by human labelers, following instructions. This programs models to be assistants.
Reinforcement Learning (RL) gets models to practice and discover optimal token sequences.
RL improves reasoning and the model's ability to "think." It is demonstrated by the DeepSeek-R1 model.
Reinforcement Learning from Human Feedback (RLHF) trains a reward model to simulate human preferences. It enables RL in unverifiable domains, but is prone to gaming.
That’s a wrap for today, see you all tomorrow.