


Document Parsing with Qwen2.5-VL and Podcast Summarizer Agent using Composio

📚 Browse past editions here.
( I write daily for my 112K+ AI-pro audience, with 4.5M+ weekly views. Noise-free, actionable, applied-AI developments only).
In today’s edition (8-Feb-25)
Document Parsing with Qwen2.5-VL - Code walkthrough
Podcast Summarizer Agent using Composio and crewai
Document Parsing with Qwen2.5-VL - Code walkthrough
Let’s parse documents using Qwen2.5-VL and converting them into HTML (or other formats) with recognized text and precise bounding boxes.
Checkout the complete Github code here.
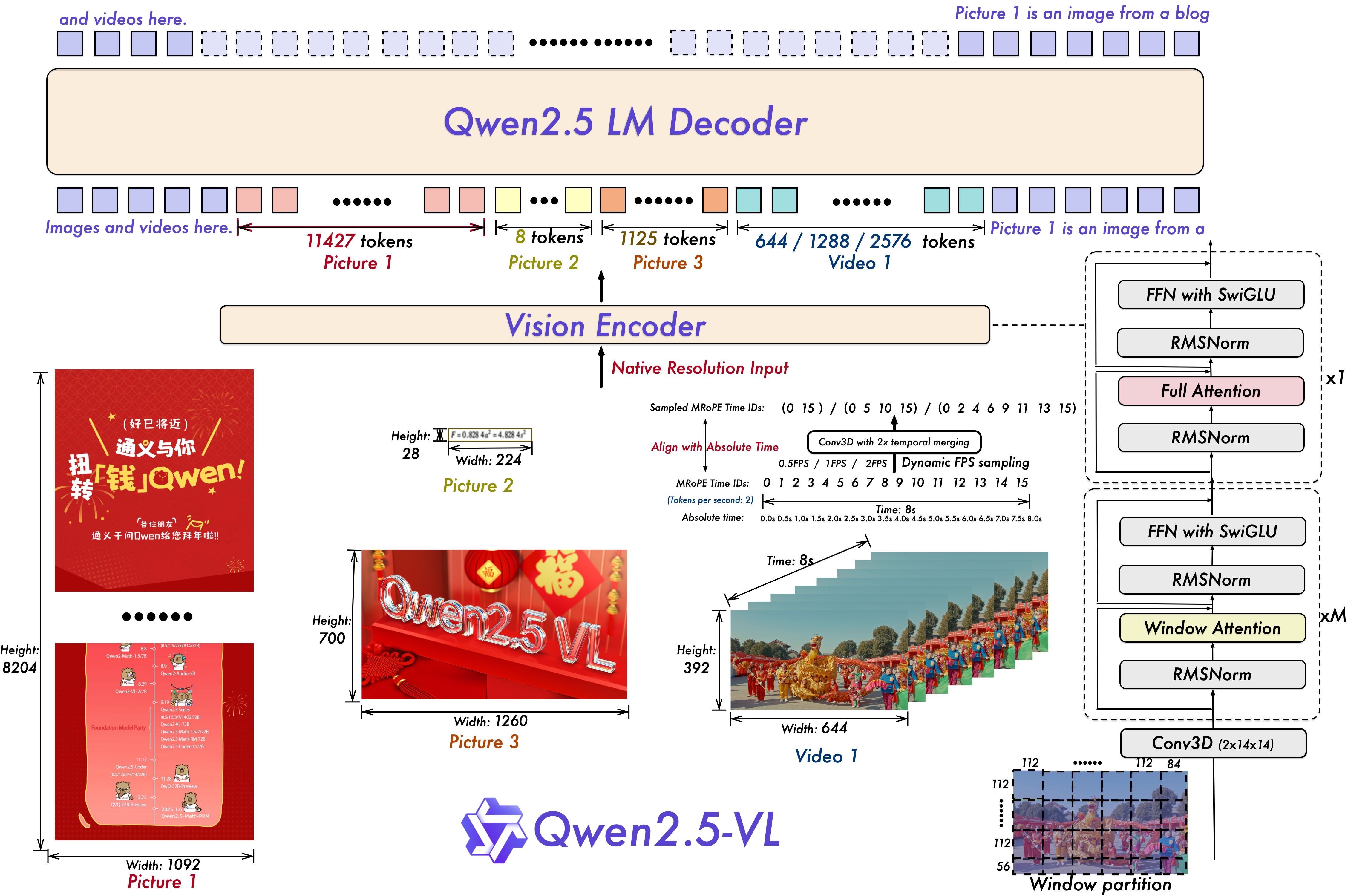
Overview
Qwen2.5-VL includes strong document parsing capabilities for text recognition and layout extraction. It can parse text in multiple languages and from various document styles, detect content bounding boxes, and produce outputs suitable for immediate reuse in downstream tasks.
It can process any image and output its content in various formats such as HTML, JSON, MD, and LaTeX.
Qwenvl HTML format
Notably, they have introduced a unique Qwenvl HTML format that includes positional information for each component, enabling precise document reconstruction and manipulation. So QwenVL HTML is a specialized HTML output from Qwen2.5-VL’s document parser. It includes recognized text and bounding box or polygon data for each fragment, allowing you to reconstruct or manipulate the original layout.
It uses standard HTML tags (like <h2>, <p>, <div>, <img>), so it's readable and can be displayed in a web browser. The "extra" part is the addition of data-bbox attributes.
: The most important part is the data-bbox attribute. This is added to the HTML tags. It stores the bounding box coordinates (x1, y1, x2, y2) of where each element (text, image, etc.) was located in the original image. This positional information is what makes it so useful.
The Qwenvl HTML format lets you:
Reconstruct the Layout: You know exactly where each piece of text or image should go when recreating the document.
Highlight and Extract: You can easily highlight specific parts of the document on the original image (like drawing boxes around words).
Manipulate the Document: You could, in theory, use this information to programmatically edit the document's layout.
Cleaning is Needed: The raw QwenVL HTML output often includes extra styling (like color) and attributes that aren't needed for basic layout. The clean_and_format_html function in the notebook is designed to remove these extras and make the HTML cleaner.
The notebook code demonstrates both local inference (using the transformers library directly) and API-based inference (using the Dashscope API).
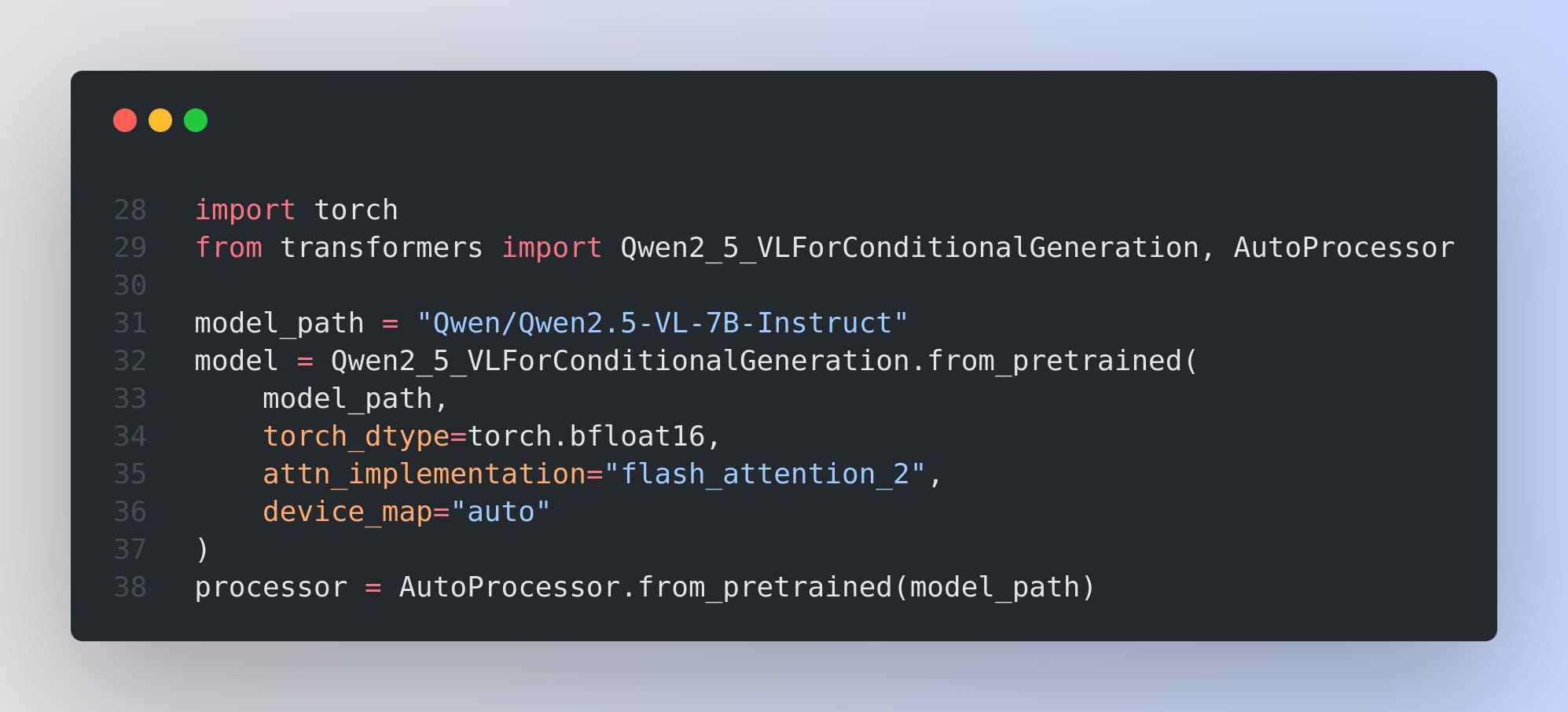
Let’s first go through the local inference (using transformers)
In below we are using Qwen2_5_VLForConditionalGeneration and AutoProcessor from the Transformers library.
Performing Document Parsing
One common approach is to provide an image containing text and request “QwenVL HTML” in the user prompt. A typical usage example might look like the following minimal snippet:
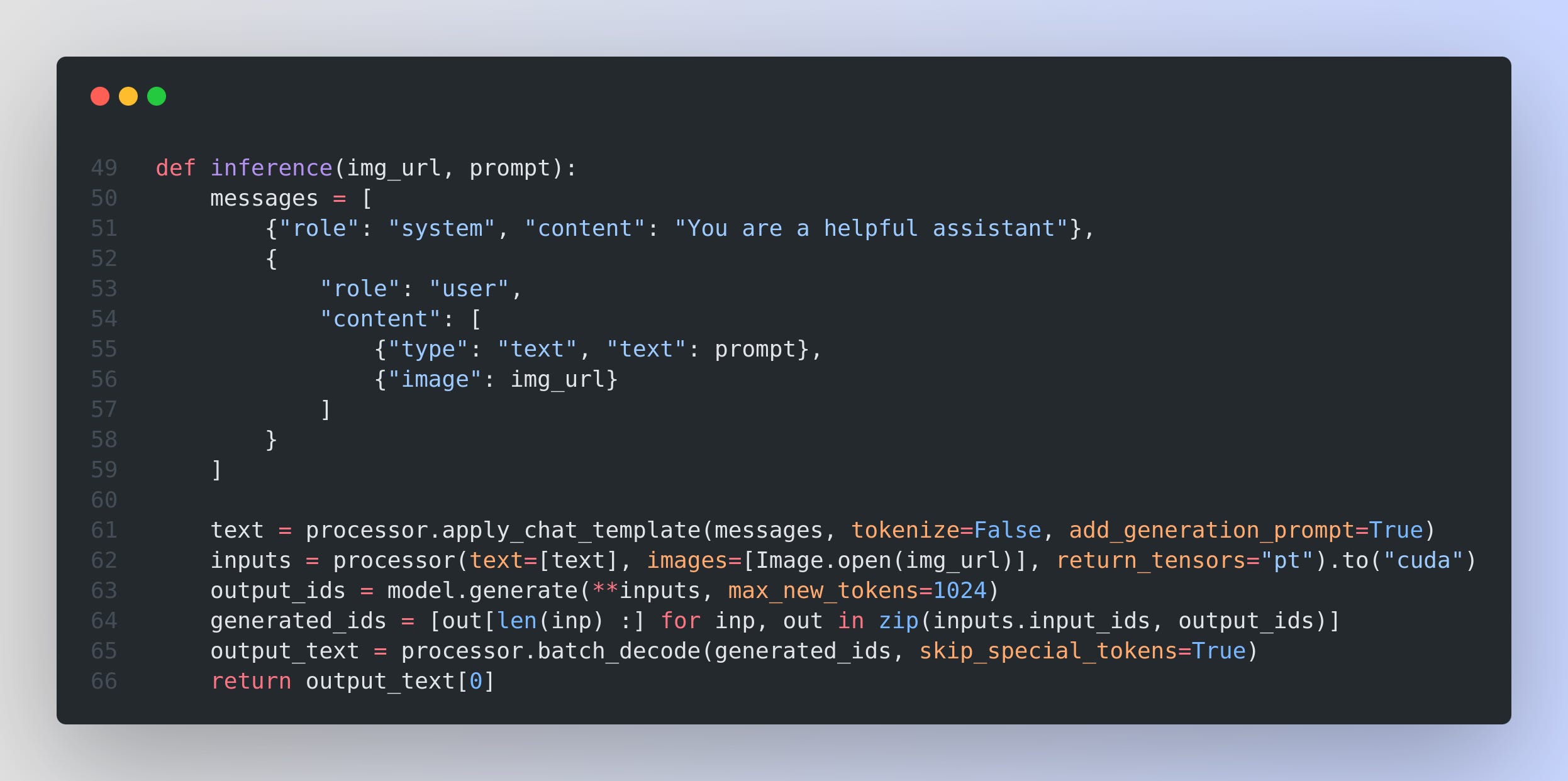
When you invoke this function with a prompt such as “QwenVL HTML” or “Parse this image into HTML,” the model returns HTML containing the document structure, detected text, bounding-box attributes (data-bbox), and other optional layout tags. This HTML is referred to as “QwenVL Document Parser” HTML.
Visualizing the Parsed Layout
Once the model generates the HTML structure with bounding boxes, you can draw them on the source image to confirm that the recognized text lines up with the correct regions.
Parsing the returned HTML with BeautifulSoup to find elements that have
data-bbox.Scaling and drawing those bounding boxes onto the original image.
Optionally drawing the recognized text directly beneath the bounding boxes.
A minimal step for visualization is:
So again the model produces HTML that includes bounding boxes (data-bbox attributes) identifying exactly where it found text. Drawing these boxes on the original image helps confirm the model’s accuracy in mapping recognized content to the right coordinates.
The above snippet takes that HTML, parses out each element’s bounding box, and then draws a rectangle plus the recognized text. That alignment check is vital because you see how each piece of text corresponds to its precise region in the original image, rather than just getting raw text with no idea where it came from. This is especially important for document parsing, where layout matters. The snippet uses BeautifulSoup to look for data-bbox, unpacks the bounding box, and calls ImageDraw methods to place red outlines and text on the image. This direct overlay reveals whether the bounding boxes actually correspond to the text in the HTML output.
Formatting the Parsed HTML
The notebook includes a routine that “cleans” and refines the QwenVL HTML output. For example, it removes extraneous color tags, merges certain overlapping style directives, or deletes empty placeholders. If you plan to incorporate the recognized text into downstream tasks, a cleaning function can help produce simpler HTML.
API-Based Inference (using Dashscope)
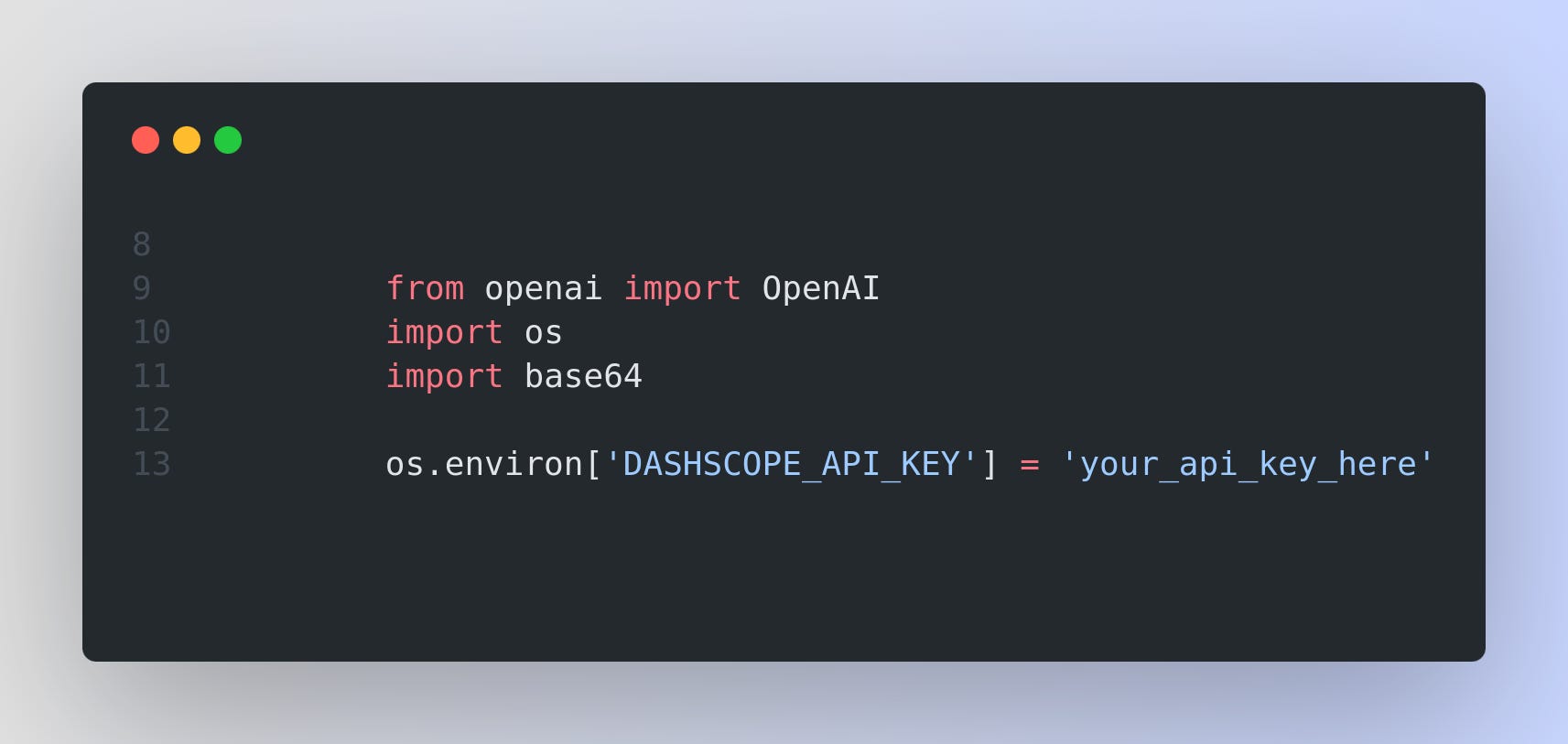
This method sends your input (image and prompt) to a remote server (Alibaba Cloud's Dashscope service) that runs the model. The server processes the input and sends back the output.
The `openai` library is used here, as Dashscope provides an OpenAI-compatible API.
Podcast Summarizer Agent using Composio and crewai

Checkout the full Github Code here and also checkout the the official composio example from where this code is adapted.
Composio helps you connect AI agents to external tools like Gmail, GitHub, Salesforce, etc.
The project takes a YouTube podcast URL, extracts and transcribes its audio, summarizes the content using an LLM (via AzureChatOpenAI), and finally sends the summary to a Slack channel. The application is launched through a simple Streamlit interface. And Whisper model for transcription.
And CrewAI is a production-grade framework designed to orchestrate complex AI agent systems. In short, it enables multiple AI agents—each with defined roles, goals, and tasks—to collaborate autonomously and efficiently. By using YAML configuration files for agents and tasks, CrewAI streamlines the process of integrating external tools and language models, making it easier to build and deploy robust, scalable applications.

The crew executes tasks sequentially. First, the transcription and summarization task runs, processing the podcast audio and converting it into a concise summary. Next, the Slack messaging task sends this summary to the specified Slack channel. This separation of concerns makes the design modular and easily maintainable.
Composio itself acts as a bridge between the AI agents and external applications. It manages secure connections (supporting protocols like OAuth and API keys) and provides a platform for integrating with various external tools. In this project, it facilitates communication with Slack and works seamlessly with the language model backend.
What is Slack Integration in Composio
Integrations in Composio are configuration objects that define how your application connects to external services (like GitHub, Slack, or HubSpot). Each integration encapsulates authentication credentials (OAuth Client ID/Secret), permission scopes, and API specifications that determine how your users can interact with the external service. These configuration objects are used to configure and manage connections with external services.
Project Structure and Configuration
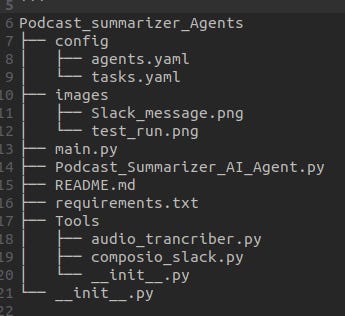
You just need to provide the YouTube URL and Slack channel name, and the application kicks off the crew’s execution process.
Flow of Project
When a user inputs the YouTube podcast URL and the Slack channel into the Streamlit interface, the following sequence occurs:
The PodSumCrew instance is created and its kickoff method is invoked with the provided inputs.
The summary agent downloads the podcast audio and transcribes it using the Whisper model.
The resulting transcription is summarized by the LLM through the configured task.
The slack agent sends the summary as a message to the specified Slack channel.
Agents, Tasks, and Crew Workflow
The core logic is implemented in the file Podcast_Summarizer_AI_Agent.py. A crew class (PodSumCrew) is defined and decorated to load the configuration files. This class sets up two agents and two corresponding tasks. The summary agent uses an audio transcription tool that downloads the audio from YouTube and employs the Whisper model for transcription. The slack agent uses a dedicated Slack tool to post the generated summary.
The entire flow is orchestrated by the crew, which handles task execution sequentially based on the configurations provided in the YAML files.
Let’s look at the @CrewBase decorator and its working
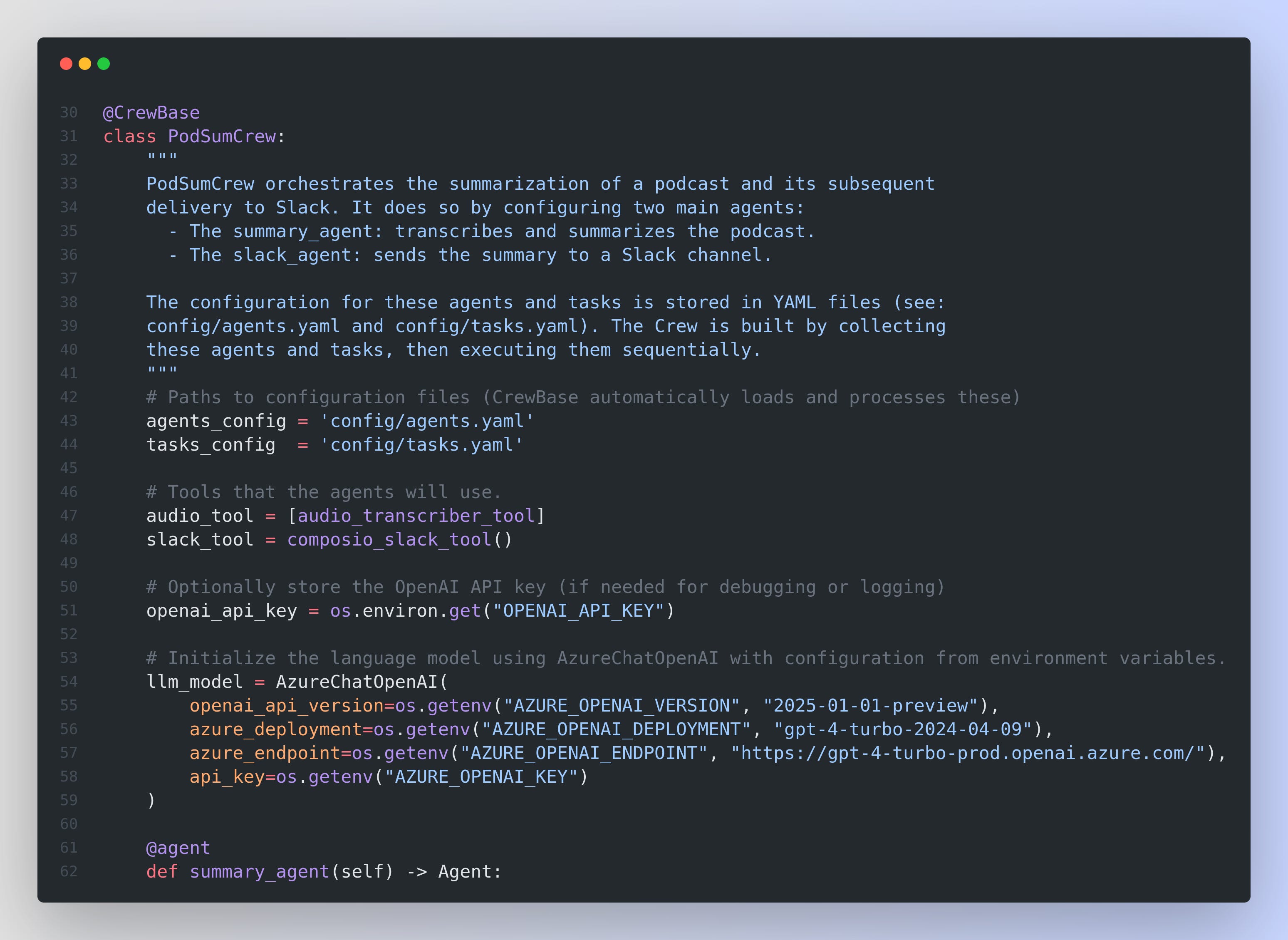
The @CrewBase decorator is essentially a marker that tells the CrewAI framework, "This class defines a crew—a group of agents and tasks that work together." Under the hood, when you decorate a class with @CrewBase, here’s what happens in simple terms:
Registration and Introspection:
The decorator scans the class for any methods marked with special decorators like @agent, @task, and @crew. It collects these methods and their associated configuration (for example, from the YAML files referenced in the class attributes) into internal registries. This means that the framework now “knows” which methods are responsible for creating agents, which ones define tasks, and which one assembles the entire crew.Configuration Loading:
The class-level attributes such asagents_configandtasks_configpoint to external configuration files (in YAML format). When the class is processed by @CrewBase, it reads these files and makes the configuration data available to the agents and tasks you define. This way, your agents (like the transcription agent or the Slack messenger) are set up with their proper roles, goals, and behaviors without hardcoding those details into your methods.Automatic Crew Assembly:
By marking the class with @CrewBase, you’re instructing the framework to automatically build a Crew object from the defined agents and tasks. The method decorated with @crew acts as the final assembler—it collects all the agents and tasks (which were registered by @agent and @task) into a cohesive unit that can later be “kicked off” to run the entire process. Essentially, it’s like defining a blueprint for how your system should run, and @CrewBase makes sure the blueprint is read, validated, and converted into a running workflow.
In summary, @CrewBase is a helper that abstracts away the manual work of collecting and wiring together all the different components (agents, tasks, and the overall crew) of your system. It lets you focus on defining what each part should do, while the framework handles the orchestration, configuration loading, and execution order automatically.
I am seeing a link here which goes to 404. It would be nice if you explain if it can be replaced by an alternative if there is noe.
client = OpenAI(
#If the environment variable is not configured, please replace the following line with the Dashscope API Key: api_key="sk-xxx".
api_key=os.getenv('DASHSCOPE_API_KEY'),
base_url="https://dashscope-intl.aliyuncs.com/compatible-mode/v1",
How would you compare qwen2vl.5vl to gemini 2 flash for pdf handling? Gemini works simpler for querying pdf and understanding graphs or pictures? While qwen better for extracting all to be used or reformatted elsewhere?