


"DIFFERENTIAL TRANSFORMER" - Outperforms Regular Transformer In Scaling Model Size And Training Tokens
For handling large contexts, DIFFERENTIAL TRANSFORMER will be a game-changer


The problem with the regular Transformer architecture
While LLMs can process long documents, they struggle with attention allocation - similar to a reader who gets distracted by irrelevant details instead of focusing on key information
Traditional Transformers exhibit a tendency to:
Spread attention too thinly across all context
Give significant weight to irrelevant information
Dilute the importance of crucial information in long texts
As context gets long, the sum of (small) attention on irrelevant tokens might be more than the attention to few individual relevant tokens, thus drowning them.
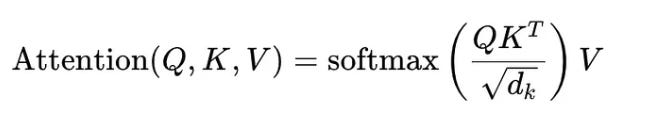
Where Q, K, and V represent query, key, and value matrices derived from input embeddings. This process allows the model to focus on different parts of a sequence when producing outputs per Attention Is All You Need.
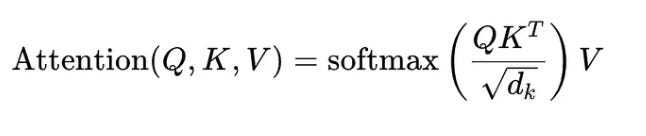
However, the problem with this standard attention is the distribution of attention scores across the entire input, often leading to attention noise; non-negligible attention given to irrelevant tokens or parts of the context, diluting the focus on truly important information.
And so here comes "DIFFERENTIAL TRANSFORMER" ✨
The architecture introduces a mathematical noise-cancellation mechanism that:
Actively identifies and amplifies relevant context
Mathematically subtracts noise through differential attention
Maintains focus on pertinent information even in long documents
Differential attention maps now subtract two distinct softmax outputs. This subtraction removes attention noise and pushes the model toward sparse attention.
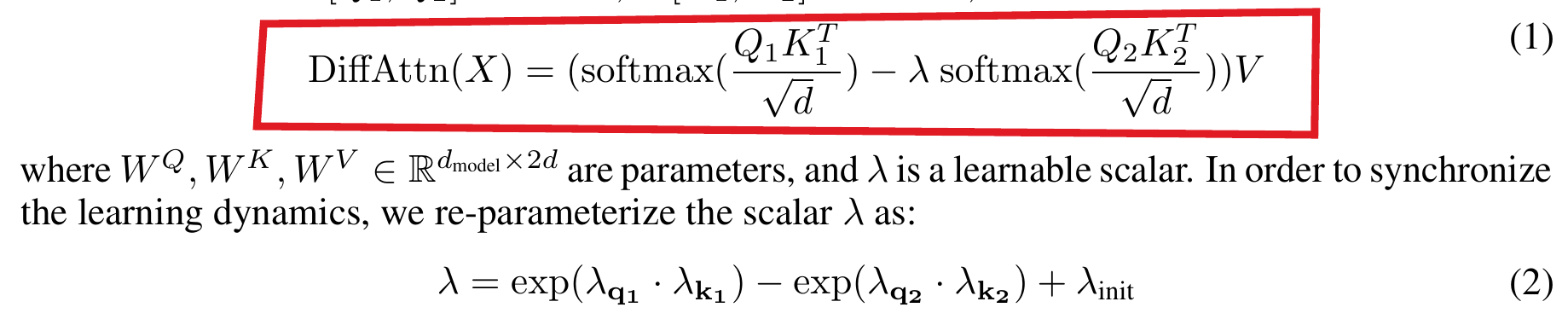
Net effect:
• Sharper retrieval and lower hallucination rates. 🏆
• Outperforms standard Transformers while using 35-40% fewer parameters or training tokens
• 10-20% accuracy gain in many-shot in-context learning across datasets
• 7-11% reduction in hallucination for summarization and question answering
• Maintains performance with 6-bit quantization, while Transformer degrades significantly
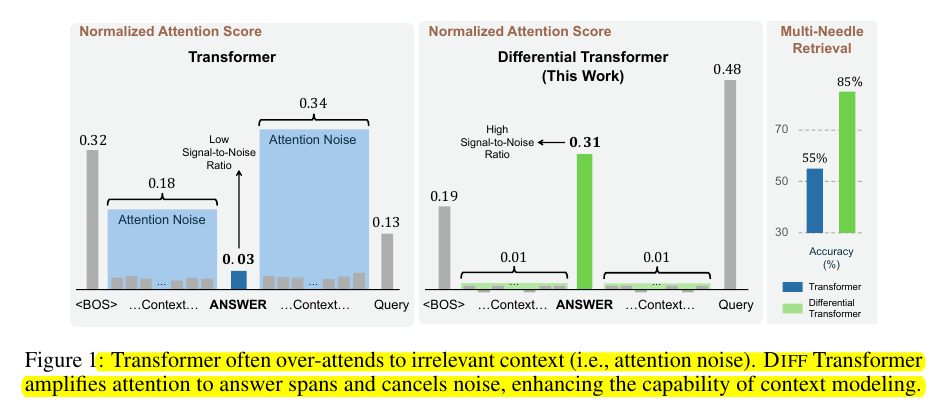
Traditional attention mechanisms use a single mapping to process contextual relationships to focus on important words or phrases in a sentence.
But the Differential Transformer introduces a dual-processing architecture that generates complementary attention representations. These attention maps focus on the same data but interpret it slightly differently — kind of like two detectives looking at the same clues but from different angles.
Once both attention maps have been created, the Diff Transformer takes the difference between them. This helps in highlighting the truly important information. This process of subtracting attention maps makes sure that only the key information gets processed further, allowing the model to “pay attention” to what really matters.
The architecture implements a form of computational noise cancellation:
Primary attention captures signal + noise
Secondary attention learns to isolate noise patterns
Subtraction operation enhances signal-to-noise ratio
The aboslute key theme of "DIFFERENTIAL TRANSFORMER"
The essence lies in pairing attention heads - meaning each processing unit in the transformer has two partners that work together
i.e. pair two attention heads, and
do:
(softmax(Q1K1) - λ softmax(Q2K2)) V
softmax(Q1K1): First attention pattern
softmax(Q2K2): Second attention pattern
λ: Learnable scaling factor
V: Value matrix for final projection

→ This creates a differential pair - while one attention head (Q1K1) learns to focus on relevant signals, its partner (Q2K2) captures patterns that should be subtracted out
→ Technical Architecture Detail The subtraction operation (-) between the two softmax patterns acts as a noise cancellation mechanism, reminiscent of differential amplifiers in electrical engineering
→ The λ Parameter λ is not fixed but learned during training, allowing the model to automatically calibrate how much of the second attention pattern should be removed
→ Engineering Efficiency This simple mathematical formulation encapsulates the entire core innovation of DIFF Transformer, requiring minimal changes to standard transformer implementations while delivering significant performance gains
The brilliance lies in its simplicity - rather than building complex architectural changes, it introduces a fundamental signal processing concept into neural network design.
Differential Transformer's practical advantage with an example use-case of research paper summarization:
→ Traditional transformer will process all content with similar attention weight. This means technical methodology sections, literature reviews, and critical findings receive equal computational focus, diminishing the model's ability to identify truly significant information.
→ The Differential Transformer will implement a sophisticated noise-reduction mechanism that operates analogously to human expert reading patterns:
First attention pathway captures comprehensive document understanding
Second attention pathway identifies less relevant contextual elements
Mathematical subtraction distills essential research contributions
🔬 The Differential Attention mechanism and its core implementation details
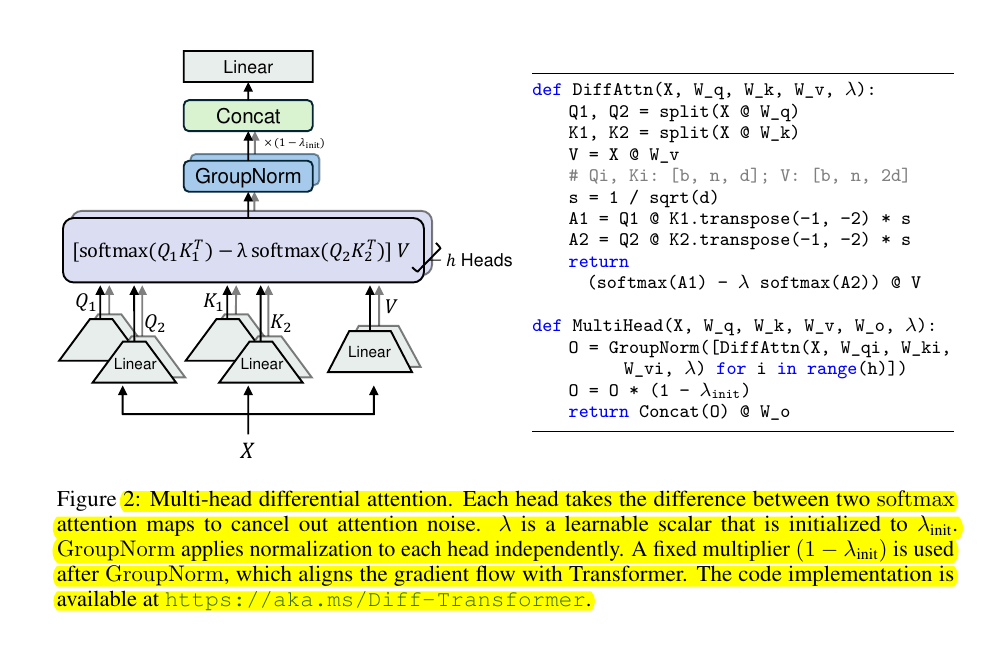
→ The mechanism splits each attention head into two parallel paths, creating differential pairs. Each pair processes the same input but learns complementary attention patterns.
Looking at the bottom of the image, we see triangular blocks marked "Linear" that branch from the input X.
→ Implementation Flow The input X undergoes parallel linear transformations to generate. These transformations generate Q1/K1 and Q2/K2 pairs. Both operate on the same input space.
Path 1: Q1, K1 (first attention component)
Path 2: Q2, K2 (second attention component)
A shared value projection V
→ Mathematically processing the crucial differential computation follows:
A1 = softmax(Q1K1^T / sqrt(d))
A2 = softmax(Q2K2^T / sqrt(d))
Final = (A1 - λA2)V
→ Normalization Strategy Post-differential computation, the architecture employs:
GroupNorm for independent head normalization
A fixed multiplier (1 - λinit) for gradient alignment
Final concatenation across heads
→ Learning Dynamics The learnable scalar λ acts as an adaptive balancing mechanism:
Initialized to λinit
Automatically adjusts during training
Controls the noise cancellation strength
→ Engineering Efficiency The implementation maintains computational efficiency through:
Shared value projections
Parallel processing paths
Efficient matrix operations
→ Key Innovation The architecture achieves noise reduction through mathematical subtraction rather than complex architectural modifications, representing an elegant solution to attention optimization.
This design demonstrates how fundamental signal processing principles can be effectively integrated into modern neural architectures.
The Diff Transformer Paper: 📚 https://arxiv.org/pdf/2410.05258
Official Code Implementation
Github: https://github.com/microsoft/unilm/tree/master/Diff-Transformer
In the above repo, the multihead_diffattn.py contains naive implementation of multi-head differential attention.

The MultiheadDiffAttn class has several sophisticated design choices:
Uses half the number of attention heads compared to standard Transformer
Supports both regular multi-head attention and grouped-query attention (GQA)
Implements RMSNorm for stability in differential computations
→ Projection Dimensionality The implementation makes efficient use of parameter space:
Query projections: Full embedding dimension
Key/Value projections: Reduced dimension accounting for head repetition
Head dimension is halved compared to standard attention
→ Lambda Parameter Engineering features a sophisticated lambda calculation:
lambda_1 = torch.exp(torch.sum(self.lambda_q1 * self.lambda_k1, dim=-1)) lambda_2 = torch.exp(torch.sum(self.lambda_q2 * self.lambda_k2, dim=-1)) lambda_full = lambda_1 - lambda_2 + self.lambda_initThis provides learnable scaling that adapts through training.
→ Attention Computation Flow in the differential mechanism is implemented through:
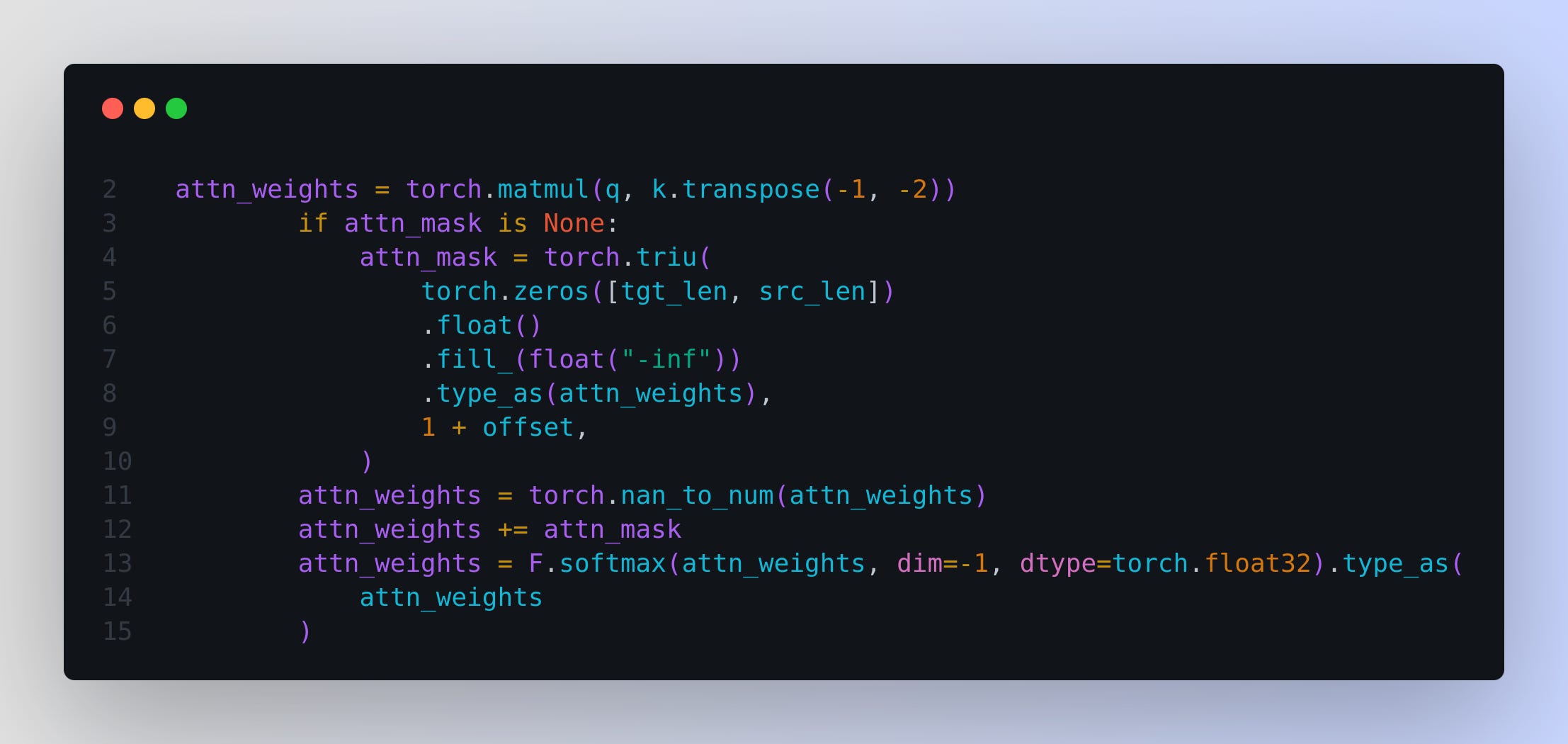
Computing standard attention weights
Reshaping to separate the two attention patterns
Applying the learned lambda scaling
Subtracting the scaled patterns
→ Optimization Features
Support for Flash Attention for efficiency
Rotary embeddings for position encoding
GroupNorm (via RMSNorm) for stable training
The lambda parameter

def lambda_init_fn(depth):
return 0.8 - 0.6 * math.exp(-0.3 * depth)The lambda_init_fn implements a depth-dependent initialization:
Base value: 0.8 (maximum initial scaling)
Decay factor: 0.6 * exp(-0.3 * depth)
Deeper layers get progressively larger initial lambda values
→ The lambda parameter serves dual purposes:
Controls the differential strength between attention patterns
Provides layer-specific calibration through depth-dependent initialization
→ This creates an adaptive noise cancellation mechanism:
Early layers: More conservative differential scaling
Deeper layers: Stronger differential effects
Learnable components allow dynamic adjustment during training