


DeepSeek-V3 Technical Report - They Just Changed The Game of AI Model Training


Reading Time: 12 minutes
Check out their Paper, GitHub Page, and Model on Hugging Face.
🎖️DeepSeek V3 from China’s leading LLM lab, achieved insanely low training cost of only $5.5 million The whole training was done in ~55 days on a 2048xH800 cluster. This is TINY compared to the Llama, GPT or Claude training runs.
It is quite fitting that DeepSeek, releases its latest model V3 on Christmas, the performance is on-par with GPT-4o & Claude 3.5 Sonnet - while trained with 10x-11x less compute.
For context the Llama-3 405B model used 30.8M GPU-hours, while DeepSeek-V3 which looks to be a stronger model, was trained only at only 2.8M GPU-hours (~11X less compute). And also DeepSeek was trained in H800’s which are a slower GPU version than Meta’s H100’s.
They just proved, resource constraints are a beautiful thing, it spark creative technical solutions.
DeepSeek-V3 introduces groundbreaking efficiency in LLM training by leveraging a Mixture-of-Experts (MoE) architecture that activates only 37B parameters out of its total 671B parameters. This selective activation approach, combined with innovative training methods, achieved state-of-the-art performance while drastically reducing training costs to just $5.5M.
If you are developing with AI Models, Deepseek V3 is on par in performance with GPT-4 and Claude 3.5 Sonnet but can be accessed at a much cheaper price.
⚙️ The Key Details

The model's foundation rests on two key architectural innovations. First, the Multi-head Latent Attention (MLA) mechanism significantly reduces memory usage during inference by compressing key-value pairs. Second, the DeepSeekMoE architecture employs 256 routed experts and 1 shared expert, where each token interacts with only 8 specialized experts plus the shared expert – effectively using about 5% of total parameters per token.
A major breakthrough comes from the auxiliary-loss-free load balancing strategy.

Traditional MoE models use auxiliary losses to prevent routing collapse, but this can hurt model performance. DeepSeek-V3 instead introduces a bias term for each expert, dynamically adjusted during training based on expert utilization. This approach maintains balanced expert load without compromising performance.
The training framework implements FP8 mixed precision training with innovative optimizations. It uses tile-wise grouping for activations (1x128) and block-wise grouping for weights (128x128), effectively handling feature outliers. The framework increases accumulation precision by promoting to CUDA cores at 128-element intervals, crucial for maintaining accuracy in large-scale training.
Communication efficiency gets a boost through the DualPipe algorithm, which overlaps computation and communication phases.

This algorithm rearranges components like attention, all-to-all dispatch, MLP, and combine operations to maximize GPU utilization. The framework achieves near-zero communication overhead by maintaining a constant computation-to-communication ratio.
The model also pioneers Multi-Token Prediction (MTP), predicting two tokens at once during training.

This approach densifies training signals and enables the model to pre-plan token generation. During inference, this translates to about 85-90% acceptance rate for the second predicted token, significantly boosting generation speed.
The inference deployment utilizes smart expert duplication strategies. High-load experts are identified and duplicated across GPUs, with careful load balancing ensuring efficient resource utilization. The system dynamically adjusts expert deployment based on usage patterns, maintaining consistent performance while maximizing throughput.
🔬 Multi-Token Prediction (MTP): One of the Secret Sauce of DeepSeek's Advanced way of Token Generation

Multi-Token Prediction (MTP) represents a sophisticated advancement in language model architecture, fundamentally changing how models approach token generation.
The traditional approach in language models predicts just one token at a time. DeepSeek-V3's MTP mechanism instead implements what they call "lookahead" modules - specialized transformer blocks that attempt to predict multiple future tokens simultaneously. The architecture maintains complete causal chains at each prediction depth, meaning each prediction considers all previous predictions in its context.
Multi-Token Prediction (MTP) augments the main Transformer model with separate modules that predict tokens beyond the immediate next one. Each MTP module is a lightweight block containing a linear projection, one transformer block, and an output head that tries to predict a future token. The process adds a second cross-entropy loss term per module, giving extra training signals for the same forward pass.
The paper retains the complete causal chain when generating each extra token. Instead of predicting multiple future tokens with a single output layer, MTP modules handle the next, next2, or next3 tokens in stages, each having its own mini-transformer sequence. This layered approach preserves causal alignment so that every predicted token’s context includes all prior tokens’ representations.
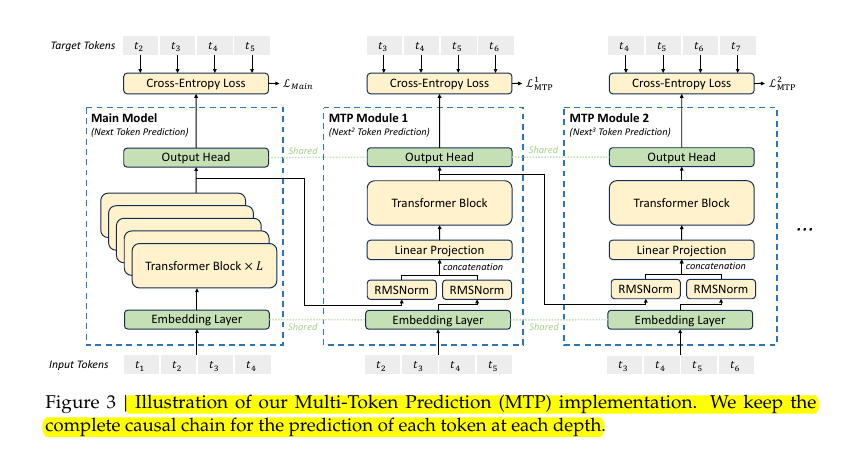
Looking at the implementation details from the image, we can see three distinct components working in parallel:
The Main Model handles standard next-token prediction (t2 given t1, t3 given t2, etc.). Alongside this, MTP Module 1 and MTP Module 2 attempt to predict tokens further into the future. Each MTP module shares the embedding layer with the main model but has its own transformer block and output head.
The technical innovation lies in how these modules process information. Each MTP module takes two inputs: the hidden state from the previous depth and the embedding of the next token. These inputs undergo RMSNorm normalization separately before being concatenated and processed through a linear projection layer. This creates a sophisticated information flow that allows the model to leverage both current context and future predictions.
The training objective becomes particularly interesting. Each prediction depth generates its own cross-entropy loss (Lmain, L1mtp, L2mtp). These losses are combined with a weighting factor λ to create the final MTP loss. This approach creates what the paper calls "densified training signals" - essentially getting more learning value from each forward pass.
The practical implications are significant. During inference, DeepSeek-V3 achieves an 85-90% acceptance rate for the second predicted token. This means the model's speculative predictions are correct most of the time, leading to significantly faster text generation. More importantly, this architecture appears to help the model develop better planning capabilities for text generation, rather than just looking at one token at a time.
What makes this particularly innovative is how it balances computational efficiency with improved model capabilities. The MTP modules add relatively little overhead during training while providing substantial benefits in both training efficiency and inference speed. The shared embedding layers and careful architecture design ensure that these benefits come without excessive computational costs.
Below is a very simplified snippet to show how MTP might be set up: (this is just an example code)
def mtp_module(main_hidden, next_token_emb, projection_matrix, transformer_block, output_head):
# main_hidden: representation from the main model or previous MTP module
# next_token_emb: embedding for the next token to predict
# projection_matrix: merges main_hidden and next_token_emb
# transformer_block: a single layer used for MTP
# output_head: shared or partially shared output projection
combined = torch.cat([RMSNorm(main_hidden), RMSNorm(next_token_emb)], dim=-1)
projected = combined @ projection_matrix
mtp_out = transformer_block(projected)
logits = output_head(mtp_out)
return logits
This code takes the hidden state from the main model (or a previous MTP module) and the embedding of the token to be predicted, concatenates them, then applies a linear projection. After passing through a small transformer block, it produces logits for the extra token’s cross-entropy loss.
This design boosts data efficiency by training the model to predict more than one token for each time-step. The main output head still predicts the next token normally, while these modules generate labeled data for tokens that lie further ahead in the sequence. Each module’s cross-entropy contributes to the total loss.
At inference time, the MTP modules are typically unused. The model reverts to standard token-by-token decoding, so performance overhead stays minimal. In practice, MTP helps the model pre-plan its next tokens during training, which can sharpen its internal representations without altering its normal generation mechanism.
Arch wise DeepSeek-V3 differs significantly from Meta
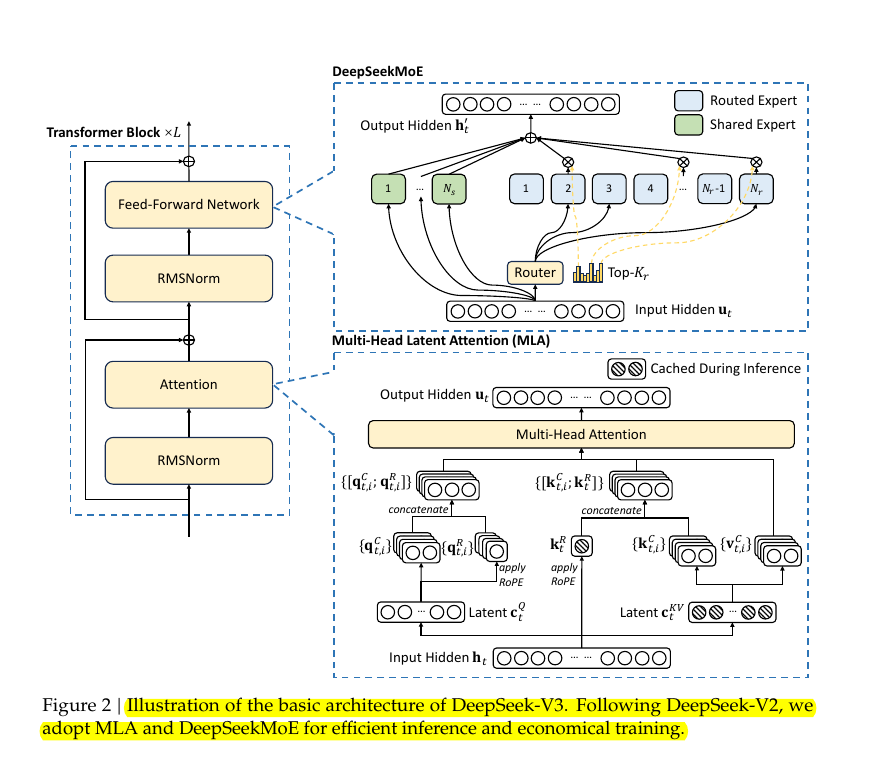
DeepSeek-V3's architecture represents a significant departure from traditional dense transformer designs, introducing two key innovations: DeepSeekMoE and Multi-Head Latent Attention (MLA).
The architecture's foundation starts with a standard transformer block structure but diverges significantly in its implementation. Instead of using a single massive feed-forward network, DeepSeekMoE splits computation across multiple specialized experts. The system employs 257 total experts - 256 routed experts and 1 shared expert, with each token accessing only 8 routed experts plus the shared expert.
Looking at the Multi-Head Latent Attention (MLA) component, we see an innovative approach to attention mechanism design.
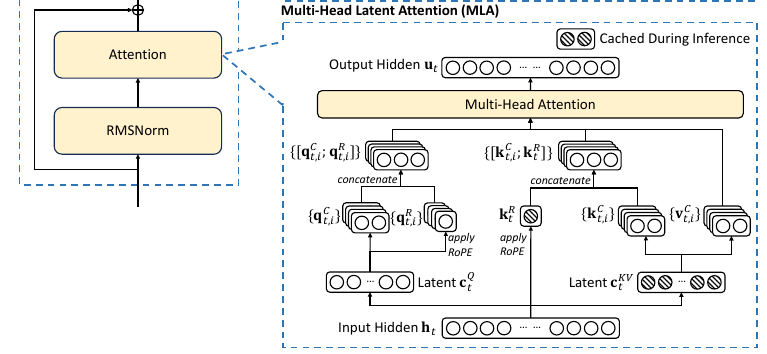
Traditional transformers store complete key-value pairs for each token, leading to massive memory requirements during inference. MLA introduces a compressed latent representation for keys and values, significantly reducing the KV cache size. This compression happens through a two-stage process:
The first stage involves generating a compressed latent vector (c_KV) that captures essential information from the input. This vector then gets projected back into the key and value spaces using separate matrices. By maintaining this compressed form during inference, MLA drastically reduces memory requirements without significantly impacting model quality.
The routing mechanism in DeepSeekMoE is particularly sophisticated. The Router component examines input features and dynamically assigns tokens to the most relevant experts. This isn't random assignment - it's learned during training, allowing the model to develop specialized experts for different types of content or tasks. The Top-Kr selection ensures each token gets processed by the most relevant subset of experts.
A crucial innovation is the auxiliary-loss-free load balancing strategy

Instead of using traditional auxiliary losses to prevent routing collapse, DeepSeek-V3 introduces dynamic bias terms for each expert. These biases get adjusted during training based on expert utilization, ensuring balanced load distribution without compromising performance.
The shared expert plays a vital role in this architecture. While routed experts specialize in specific patterns or tasks, the shared expert provides a baseline capability available to all tokens. This hybrid approach ensures the model maintains strong general capabilities while allowing for specialized processing when needed.
During inference, the system caches certain components (marked with crossed boxes in the diagram) to optimize performance. This caching strategy, combined with the compressed MLA representations, enables DeepSeek-V3 to achieve both high performance and efficient inference despite its large total parameter count.
The architecture's success lies in its ability to maintain high model capacity (671B parameters) while keeping active computation low (37B parameters per token). This efficiency comes without the traditional trade-offs in model quality, representing a significant advancement in large language model design.
Analyzing the Mixture Of Expert architecture in this model
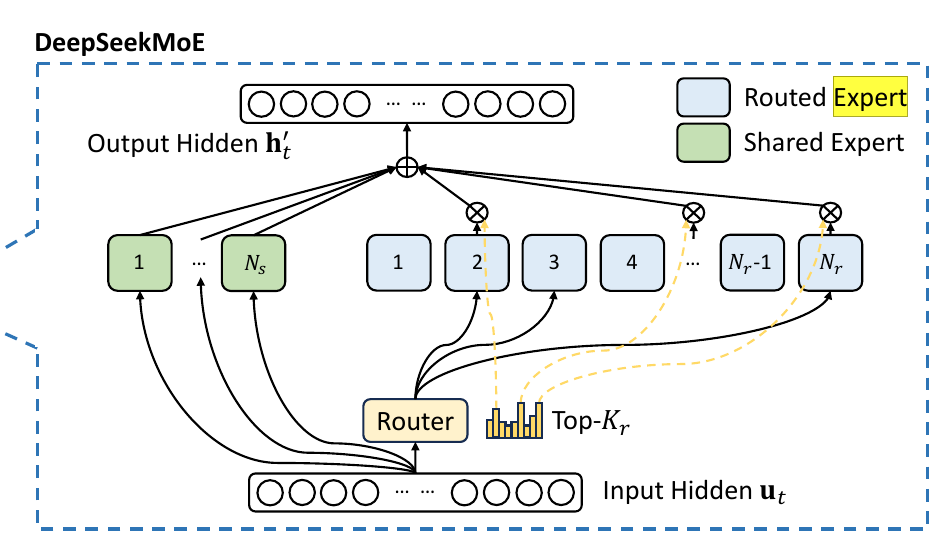
The model employs a dual-category expert system:
Shared Experts (Ns)
Displayed in green blocks on the left
Number: 1 shared expert
These experts process all inputs, providing baseline computational capability
Routed Experts (Nr)
Displayed in gray blocks on the right
Number: 256 routed experts
The router dynamically selects top-Kr (8) experts for each token
The routing mechanism employs a novel approach to expert selection. For each token, the system activates only 8 specialized experts plus the shared expert.
Meaning only 9 out of 257 experts process each token. This translates to a remarkable sparsity factor of ~28.6x (257/9) , significantly reducing computational overhead during inference.
A critical innovation lies in the auxiliary-loss-free load balancing strategy. Instead of using traditional auxiliary losses to prevent routing collapse, the system introduces a bias term bi for each expert. The equation for expert selection becomes:

This bias term gets dynamically adjusted during training: decreased when an expert is overloaded and increased when underloaded. The adjustment speed γ serves as a hyperparameter controlling this balancing act. Crucially, while the bias affects routing decisions, the gating value still derives from the original affinity score si,t, preserving model performance.

The implementation also includes node-limited routing to optimize communication costs. Each token gets routed to at most M nodes, selected based on the highest Kr/M affinity scores per node. This constraint enables nearly full computation-communication overlap during training.
What makes this architecture particularly effective is its no token-dropping policy. The balanced load distribution achieved through the bias-based routing means every token gets processed during both training and inference. This contrasts with some MoE implementations that drop tokens to maintain load balance.
During deployment, the system implements smart load balancing through expert duplication. High-demand experts get duplicated across nodes based on usage statistics, with continuous monitoring and adjustment ensuring optimal resource utilization. This adaptive approach maintains performance while maximizing throughput.
The success of this architecture lies in its ability to maintain both high model capacity and computational efficiency. While the total parameter count reaches 671B, each token effectively uses only about 37B parameters, achieving impressive performance with significantly reduced computational overhead.
The real innovation here isn't just in the numbers - it's in how DeepSeek has solved the traditional MoE challenges of load balancing and communication overhead through elegant architectural choices and dynamic optimization strategies.
A sparsity factor of ~28.6x in a Mixture-of-Experts (MoE) model can be beneficial if the gating mechanism is well-trained and routes tokens to the most appropriate experts. This approach can reduce the computational burden on each forward pass since tokens avoid passing through all experts at once, effectively lowering the capacity requirements for each inference step. However, an extremely high sparsity factor can introduce complexity in balancing expert utilization, as some experts might receive significantly more workload than others if the gating is not carefully managed.
With a high number of experts, the model’s overall capacity is large, but the active set per token remains small. This is often a desirable property in MoE setups because it keeps the per-token computation more manageable without sacrificing the total parameter count.
The optimal performance with this model depends on the hardware resources, training stability, and the distribution of expert usage across domains. If the gating remains stable and properly balanced, this level of sparsity can lead to stronger performance and lower compute overhead compared to fully dense alternatives.
👨🔧Can I run DeepSeek-V3 locally?
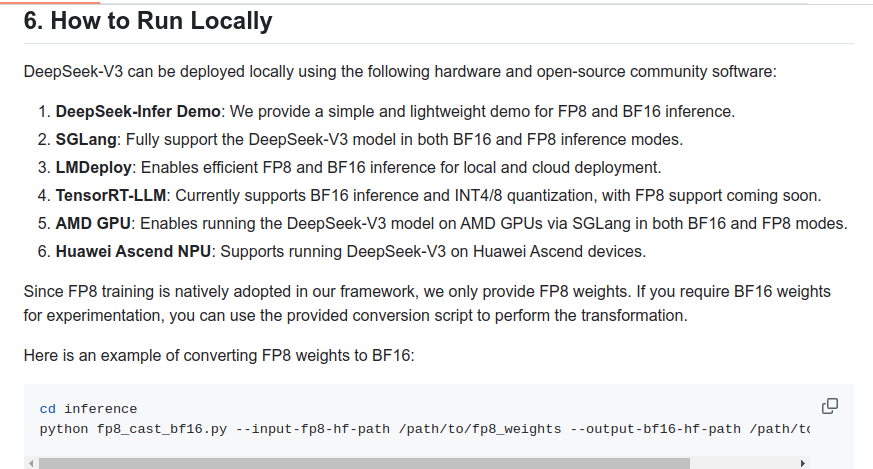
The model will take at least 350-700 GB of RAM/VRAM (depends on quant), given its 671B parameters size, (for context, the largest Llama is 405B).
The total size of DeepSeek-V3 models on HuggingFace is 685B, which includes 671B of the Main Model weights and 14B of the Multi-Token Prediction (MTP) Module weights.
You aren't force to use VRAM here, because DeepSeek V3 has 37B active parameters which means it will perform at usable speeds with CPU-only inference. The only problem is that you still need to have all parameters in RAM.
This model is 671B parameters; even at 4bpw you are looking at 335.5GB just for the model alone, and then you need to add more for the kv cache. So Macs are also out of the question unless Apple comes out with 512GB models.
Nice write up! Took me a bit to understand the moe and routing relevance on vram, plus the context size. This confirms the low end of the numbers I was calculating. Appreciate the math in public!😁