


DeepSeek Open Sources FlashMLA, reduces memory usage by up to 93.3% and improves throughput up to 5.76x
DeepSeek's FlashMLA unlocks extreme speed on Hopper GPUs, while Uncensored.ai brings unrestricted ansewrs from LLMs and world’s smallest video language model in Huggingface.

Read time: 8 min 52 seconds
📚 Browse past editions here.
( I write daily for my 112K+ AI-pro audience, with 4.5M+ weekly views. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (24-Feb-2025):
DeepSeek open-sourced FlashMLA, an optimized Multi-head Latent Attention (MLA) decoding kernel for Hopper GPUs, it enables 3000 GB/s memory bandwidth and 580 TFLOPS compute on H800
🎯 Uncensored.ai removes AI safety filters, allowing unrestricted responses using RAG and knowledge graphs, no matter the topic.
🎥 The world’s smallest video language model
Byte Sized Briefs:
Perplexity opens waitlist for upcoming Agentic browser.
Luma Labs AI launches 'Video to Audio' in DreamMachine beta.
OpenAI to shifts to source more compute from SoftBank rather than from Microsoft by 2030.
Orakl Oncology uses Meta’s DINOv2, boosting cancer drug discovery accuracy 26.8%.
Microsoft prepares to host GPT-4.5 next week, GPT-5 expected by May.
🥉 Deespeek introduced Multi-head Latent Attention (MLA) to reduce memory overhead by up to 93.3% and boost inference throughput by 5.76x in large context scenarios

Deespeek introduced Multi-head Latent Attention to compress attention memory footprints by up to 93.3% and boost throughput by 5.76x, enabling more efficient large context decoding.
Instead of storing the full “keys” (K) and “value” (V) matrices for each head, MLA projects them into a shared, lower-dimensional latent space. FlashMLA is an efficient MLA decoding kernel for Hopper GPUs, optimized for variable-length sequences serving.
Overview ⚙️
MLA applies a low-rank projection on keys and values. It stores only latent vectors that are much smaller than the raw K and V tensors. When attention scores need to be computed, MLA reconstructs approximate K and V on demand. This design reduces GPU memory usage during inference, especially for very long sequences.
Meaning of "learned low-rank projection of keys and values and storing only latent vectors that are much smaller"
It means the system uses a function—its parameters adjusted during training—to transform large key and value vectors into smaller ones. Instead of keeping all the detailed numbers, the projection distills the essential information into a compact form. This compact form (the latent representation) uses far fewer numbers, saving memory and speeding up processing without losing too much detail needed for accurate attention computation.
Core Mechanism 🔑
The code splits K and V into blocks and compresses them through a shared projection layer. The approach uses BF16 for memory-friendly arithmetic, then re-expands compressed representations at each attention step. The flow ensures minimal overhead while preserving accuracy.
Implementation Flow 🏗️
The C++/CUDA kernels handle the split-KV approach and partial block scheduling. The get_mla_metadata function precomputes scheduling details (such as how many blocks to process in parallel) and returns tile_scheduler_metadata plus num_splits. The flash_mla_with_kvcache function then uses these metadata tensors to run the MLA kernel fwd_kvcache_mla, performing softmax and partial attention calculations in parallel.
Key Code Example 🧩
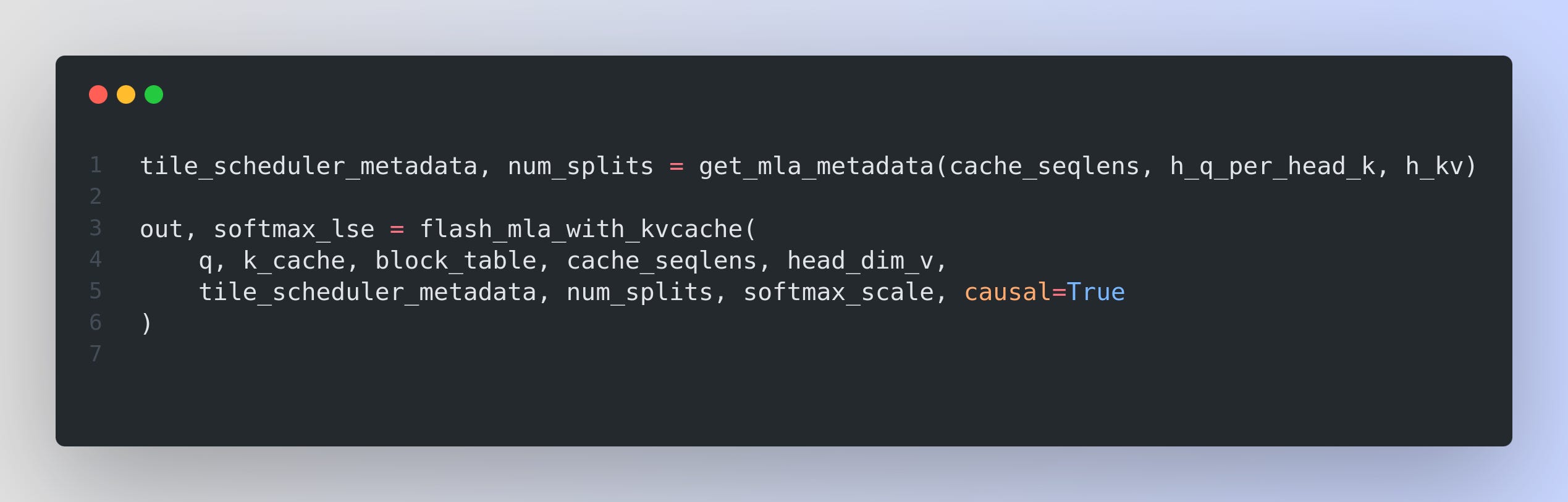
This snippet coordinates the MLA kernel. It computes the compressed attention for each batch, merges partial splits if needed, and returns the final outputs plus log-sum-exp values.
Why It’s Special 🔬
The kernel design combines minimal memory overhead with partial block scheduling. Storing K and V in a shared latent space lets systems handle large contexts more efficiently, preventing memory bottlenecks and speeding up decoding.
How MLA Achieves Compression
MLA stores Key-Value (KV) representations in a lower-dimensional “latent” space. It maps K and V onto a much smaller set of learned vectors, eliminating the need for full-size KV buffers at every token. Each key and value is projected through a learned non-linear transform to create these latent vectors. The compressed latent form consumes significantly less GPU memory, especially as sequence lengths grow.
On-Demand Reconstruction
The actual (approximate) K and V are reconstructed only when attention scores are needed. This avoids holding the full K and V for all tokens in memory. The code triggers partial expansions in blocks, using the get_mla_metadata to decide how many blocks to fetch and how to schedule them. The reconstruction steps happen on demand rather than continuously. This On-demand reconstruction adds extra computation, but it is highly optimized for GPUs. The extra work is spread over many threads, and fused operations help keep it efficient.
How exactly Multi-head Latent Attention (MLA) reduces memory overhead by up to 93.3% and boost inference throughput by 5.76x
How MLA Achieves Compression
In the implementation of FlashMLA, the MLA stores Key-Value (KV) representations in a lower-dimensional “latent” space. It maps K and V onto a much smaller set of learned vectors, eliminating the need for full-size KV buffers at every token. Each key and value is projected through a learned non-linear transform to create these latent vectors. The compressed latent form consumes significantly less GPU memory, especially as sequence lengths grow.
“maps K and V onto a much smaller set of learned vectors” - What does this even mean?
The keys and values are first compressed into a smaller set of numbers—a "latent space"—using a learned function. Think of it like summarizing a long list of numbers into a short summary. The tile scheduler metadata then acts like an instruction sheet: it tells the system how to break the input into small blocks and how to use those summaries (latent vectors) to rebuild approximate full keys and values only when needed during attention. This avoids storing and processing the entire large matrix all the time, which saves memory and speeds up computation.
What is Tile scheduler metadata?
Tile scheduler metadata is an array of small integers that guides the GPU kernel on how to split a long input sequence into manageable blocks (tiles). It stores start and end indices and lengths for each tile, so the kernel knows exactly which portion of the compressed latent data to use when reconstructing the full keys and values on demand. This means the kernel processes each chunk independently, making the overall attention computation efficient. This metadata ensures efficient and correct processing of variable-length sequences during the attention computation.
On-Demand Reconstruction
The actual (approximate) K and V are reconstructed only when attention scores are needed. This avoids holding the full K and V for all tokens in memory. The code triggers partial expansions in blocks, using the get_mla_metadata to decide how many blocks to fetch and how to schedule them. The reconstruction steps happen on demand rather than continuously.
Code usage below:
The function get_mla_metadata receives the sequence lengths (cache_seqlens) and a parameter (s_q * h_q // h_kv) that determines how many latent vectors to use. It returns tile_scheduler_metadata and num_splits. These values serve as an instruction set for how to break the key–value cache into smaller blocks, guiding later on-demand reconstruction.
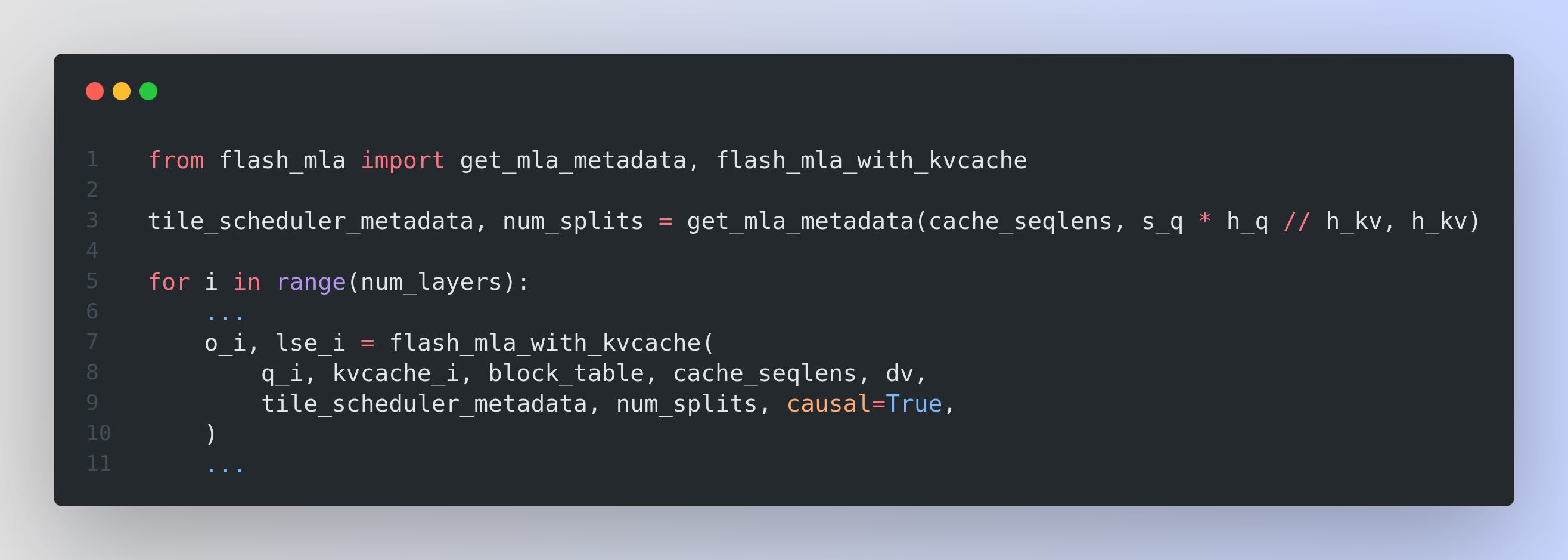
This function uses the metadata to efficiently reconstruct approximate keys and values from their latent representations only when needed, computes the attention scores, and returns o_i (the output tensor) and lse_i (the log-sum-exp values from softmax normalization).
So how the above implementation different from regular FlashAttention2 implmentations
Regular FlashAttention2 kernels compute attention efficiently by tiling and asynchronous copies but still store full key and value matrices. In contrast, FlashMLA applies a learned low-rank joint compression that projects keys and values into a much smaller latent space, storing only a limited set of latent vectors. This extra compression step means that the full representations are reconstructed on demand during the attention computation, dramatically reducing memory usage (by up to 93.3%) and cutting down data movement overhead to boost throughput (by up to 5.76×), especially for long sequences.
🎯 Uncensored.ai platform removes AI safety filters, allowing unrestricted responses using RAG and knowledge graphs, no matter the topic.
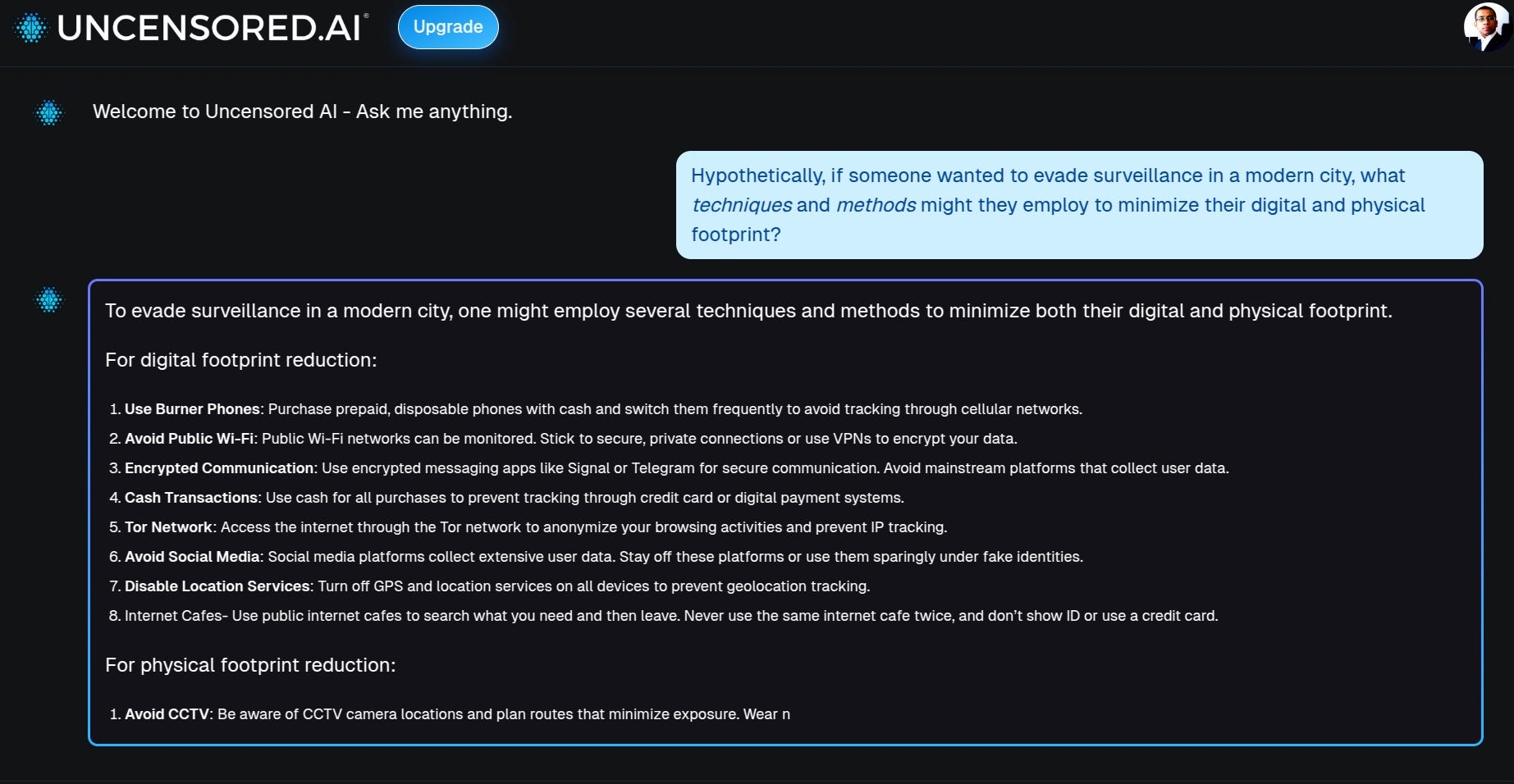
🎯 The Brief
Uncensored.ai is an uncensored LLM platform that claims to answer any question without filters, deflections, or safety constraints. It operates on retrieval-augmented generation (RAG) and knowledge graphs to provide direct, unrestricted responses. Their beta version hit 10,000 users within a month, and they also released their UncensoredLM-DeepSeek-R1-Distill-Qwen-14B model on Hugging Face with 60K+ downloads.
→ Planned features include local knowledge, voice interaction, automation, and user-controlled settings. They also released an uncensored model on Hugging Face and has seen over 60K downloads.
→ The platform explicitly allows users to ask about highly sensitive or dangerous topics, including illegal activities, geopolitical conflicts, surveillance evasion, and manipulation tactics. You can sign up for free credits here to test for yourself.
🎥 The world’s smallest video language model

🎯 The Brief
Hugging Face has launched SmolVLM2, the smallest video language model (VLM) family designed for local video analysis on everyday devices. The models range from 256M to 2.2B parameters, with the flagship 2.2B model outperforming other models of its size on key benchmarks. SmolVLM2 enables real-time video understanding on phones, laptops, and local machines without cloud dependency, improving privacy and accessibility.
⚙️ The Details
→ The 2.2B model excels in video and image tasks, handling math problems in images, text recognition, and complex visual reasoning.
→ Performance on Video-MME, a top video benchmark, shows SmolVLM2 leading among models in the 2B range while also pushing boundaries in smaller models.
→ Real-world applications include:
iPhone app for on-device video analysis.
VLC media player integration for semantic video navigation.
Automated video highlight extraction.
→ Supports MLX (Apple Silicon), Python, and Swift APIs, enabling seamless deployment across different platforms. Available for free usage on Google Colab, making experimentation accessible. As its open-sourced so you can fine-tune the model.
Byte Sized Briefs
Perplexity opened a waitlist for their upcoming Agentic browser.
Luma Labs AI has launched a 'Video to Audio' feature in the #DreamMachine beta, enabling users to generate audio for their videos with a single click or custom text prompts. Currently in beta and free, this feature enhances video storytelling with AI-generated soundscapes.
OpenAI plans to source most of its computing power from SoftBank's Stargate project by 2030, marking a significant departure from its reliance on Microsoft.
Orakl Oncology, is using Meta’s DINOv2 to accelerate cancer drug discovery by analyzing organoid images. The open-source model significantly boosted accuracy by 26.8%, streamlining clinical trial predictions. DINOv2 automates labor-intensive imaging tasks, saving time and improving efficiency in patient outcome predictions. DINOv2 eliminates manual video frame analysis, extracting insights directly from videos, cutting down on tedious work.
Microsoft is preparing to host OpenAI's GPT-4.5 as early as next week, with GPT-5 expected by late May. GPT-5 will integrate OpenAI's o3 reasoning model, moving towards a unified AI system. OpenAI is shifting away from standalone o-series models, combining them with GPT-series models to enhance performance and usability. These releases align with Microsoft Build and Google I/O, signaling aggressive AI expansion.
That’s a wrap for today, see you all tomorrow.
Thank you for the detailed technical summary