


🚨 Alibaba's Wan2.1: Text to Video in 4 Minutes, 8.19GB VRAM on RTX 4090
Alibaba’s Wan2.1 generates videos in 4 minutes, OpenAI publishes its system card, and AI players shake up coding, automation, audiobook royalties, and voice assistant pricing.

Read time: 6 min 27 seconds
📚 Browse past editions here.
( I write daily for my 112K+ AI-pro audience, with 4.5M+ weekly views. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (26-Feb-2025):
🚨 Alibaba's Wan2.1: Text to Video in 4 Minutes, 8.19GB VRAM on RTX 4090
🏆 OpenAI Finally Published its Deep Research System Card
📡 DeepSeek Launches DeepGEMM: 1350+ TFLOPS With 300-Line FP8 Kernel
🗞️ Byte-Size Briefs:
DeepSeek accelerates R2 release with stronger coding and multilingual support.
ElevenLabs launches AI audiobook monetization, challenging Audible with better royalties.
Convergence AI unveils Proxy Lite, a 3B model excelling in web and GUI automation.
OpenAI extends deep research to all paid ChatGPT tiers with limits.
OpenAI expands Advanced Voice Mode, adding screen-sharing for Pro users.
Microsoft makes Copilot Voice and Think Deeper free, Pro keeps priority.
DeepSeek offers off-peak discounts: 50% on V3, 75% on R1 pricing.
🚨 Alibaba's Wan2.1: Text to Video in 4 Minutes, 8.19GB VRAM on RTX 4090
🎯 The Brief
Alibaba’s Tongyi Lab introduced Wan2.1, an open-source text-to-video suite that surpasses other models and runs on a single consumer-grade GPU. Wan2.1 runs on an RTX 4090 with 8.19 GB VRAM for its T2V-1.3B variant, generating 480P video in about 4 minutes.
⚙️ The Details
The model is available in two versions: T2V-1.3B, a lightweight model with 1.3 billion parameter, that can run easily on Laptops with just 8.19GB of video memory, and a more powerful T2V-14B version with 14 billion parameters.
For image-to-video generation, it offers two resolution options: I2V-14B-720P for 720p videos and I2V-14B-480P for 480p videos.
The model excels at simulating complex body movements and tracking spatial-temporal details, which means it creates smooth, natural motion sequences while enhancing image quality and adhering to physical laws.
It leverages a 3D Variational Autoencoder for spatio-temporal compression, chunked frames, and causal convolutions to prevent memory bottlenecks. A Flow Matching Diffusion Transformer with cross-attention and time-aware MLP processes multilingual text.
Training employs Fully Sharded Data Parallel, and inference is accelerated by Context Parallel. It supports text-to-video, image-to-video, inpainting, outpainting, bilingual text rendering, and a T2V-14B variant for near-linear scaling in distributed setups.
The model is available across multiple platforms, including Alibaba Cloud’s AI Model Community, ModelScope, and Hugging Face.
🏆 OpenAI Finally Published its Deep Research System Card
🎯 The Brief
OpenAI rolls out Deep Research system card. It’s labeled medium risk after new red teaming. Explains how it implemented Blocklists, output filters, and a sandbox limit malicious use. DeepResearch offers stronger privacy guardrails and improved refusal for disallowed content.
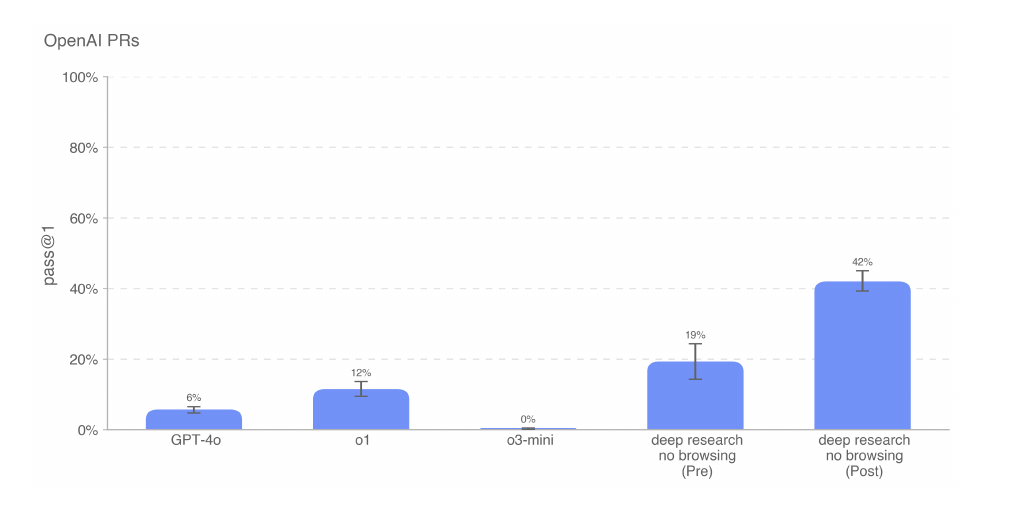
This chart above shows the DeepResearch’s significantly improved success rate on real OpenAI pull-request tasks. Pre-mitigation deep research only hit 19%, but the post-mitigation version jumps to 42%, surpassing older models by a wide margin.. Deep research can tackle practical coding problems in a way previous releases couldn’t.
⚙️ The Details
• Deep Research uses new browsing datasets and a chain-of-thought grader. It reads external content, runs Python in a sandbox, and relies on search to reduce hallucinations.
• Tests show 68% pass rates on real software tasks and 70% success on top-tier cybersecurity challenges. More robust privacy scans reject personal data requests, while a blocklist denies disallowed content.
• Mitigations address prompt injections, jailbreaks, and risky queries. A custom Preparedness evaluation flagged potential for malicious code or persuasion, but found no high-risk escalations.
📡 DeepSeek Launches DeepGEMM: 1350+ TFLOPS With 300-Line FP8 Kernel
🎯 The Brief
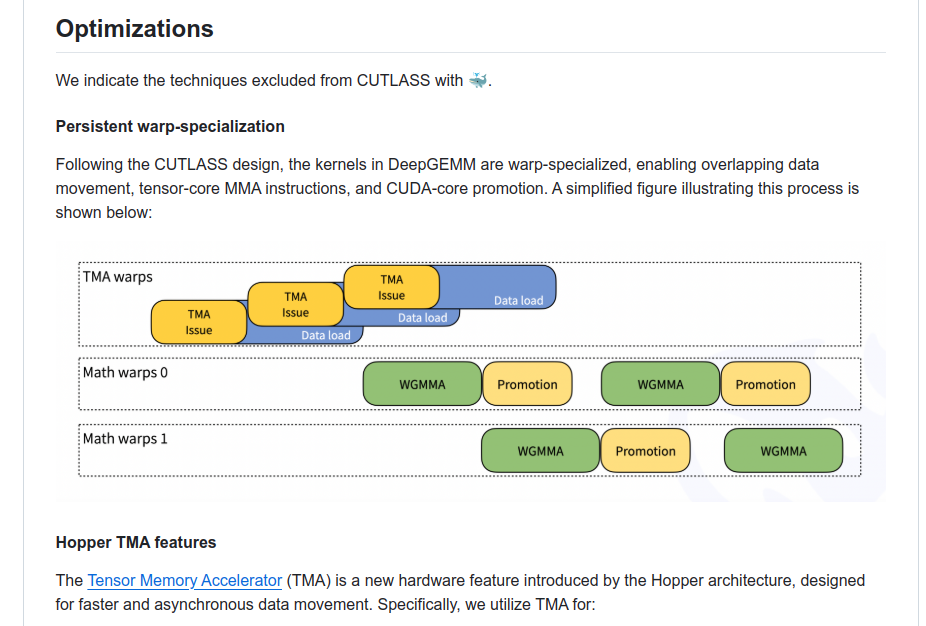
DeepSeek open-sources DeepGEMM, an FP8 library handling dense and MoE GEMMs on NVIDIA Hopper with over 1350 TFLOPS. Its core logic spans ~300 lines and outperforms specialized kernels, benefiting high-efficiency training and inference. Its a clean FP8 GEMM library using TMA and row-block scaling to push matrix multiplication performance on Hopper GPUs. It achieves strong speedups for dense and MoE GEMMs through binary-level optimizations and JIT compilation.
⚙️ The Details
DeepGEMM supports normal and grouped MoE GEMMs, using TMA for loads, stores, and multicasts. It applies fine-grained scaling for FP8 and uses two-level accumulation to address Hopper’s accumulation constraints.
Performance tests show up to 2.7x speedup for certain dense shapes and around 1.2x for grouped MoE layouts. The library uses about 300 lines in a single kernel, yet consistently matches or outperforms specialized implementations.
Its fully JIT design compiles kernels at runtime with parameters treated as compile-time constants, improving performance on small shapes. This removes static installation overhead and offers more flexible block sizes.
Requirements include Python 3.8+, CUDA 12.3+ (12.8 recommended), PyTorch 2.1+, and CUTLASS 3.6+. The project is MIT licensed and keeps code minimal for easier debugging and enhancement.
So how exactly DeepGemm achieves 2.7x speedup over CUTLASS 3.6 on normal GEMMs and around 1.1–1.2x on grouped MoE tasks.
DeepGEMM uses asynchronous TMA loads/stores and row/block-level FP8 scaling to move data faster, reducing the usual memory waiting time found in standard GEMM libraries. By compiling each kernel at runtime with matrix dimensions treated as compile-time constants, it fully unrolls loops, saving registers and boosting small-shape performance.
On top of that, it tweaks FFMA instructions at the assembly level, flipping yield and reuse bits. This optimization allows warp switching to happen more smoothly, improving parallelism and throughput. Finally, flexible block sizes avoid idle SMs on odd shapes, delivering higher utilization and resulting in those 2.7x and 1.1–1.2x gains.
🗞️ Byte-Size Briefs
DeepSeek is expediting R2’s release to leverage R1’s momentum. Instead of the early May target, it’s coming out sooner. R2 will include stronger coding features and add multiple languages. GPT-4.5 is launching soon, and DeepSeek wants to stay in front of the AI race.
ElevenLabs is offering a new way for authors to release AI-generated audiobooks via its Reader app, building on a collaboration with Spotify for AI narration. It aims to take on Audible by delivering stronger royalties and a space for indie creators. Authors can earn roughly $1.10 for each listener who stays 11 minutes or more. It’s open to U.S.-based authors in English, with plans to cover 32 languages.
Convergence AI rolled out Proxy Lite, a 3B-parameter vision-language model riding on Qwen2.5-VL-3B-Instruct. It tackles browser automation like a pro, even on lean hardware. It secured 72.4% on WebVoyager, eclipsing many open-source generalists. Checkout the model in HuggingFace. Proxy Lite has been carefully evaluated using the WebVoyager benchmark, a comprehensive set of tasks designed to test web automation capabilities. The model achieved an overall score of 72.4%, a strong performance indicator given its open-weights nature.
OpenAI has extended deep research to all ChatGPT Plus, Team, Edu, and Enterprise users. It references uploaded files more accurately and sets monthly usage at 10 queries for standard tiers, 120 for Pro. Built using inputs from many domain experts, it boosts retrieval precision and trustworthiness.
OpenAI expanded Advanced Voice Mode to all ChatGPT tiers, using a lightweight GPT-4o mini model. Free users get natural voice interactions with a lower rate, while Plus retains higher limits and Pro adds screen-sharing features.
On a related note, Microsoft’s Copilot Voice and Think Deeper also went free, but Pro subscribers keep priority on advanced models within Microsoft 365. Both announcements underscore growing accessibility for AI-driven conversational tools.
DeepSeek is running off-peak discounts from 16:30–00:30 UTC daily for DeepSeek-V3 and DeepSeek-R1. Prices drop 50% for DeepSeek-V3 and 75% for DeepSeek-R1, cutting costs on input and output tokens. So with Discounted price you get DeepSeek-R1 at usd 0.035 input / 0.550 ouput per million tokens.
That’s a wrap for today, see you all tomorrow.